Data quality and Airflow
Overview
Checking the quality of your data is essential to getting actionable insights from your data pipelines. Airflow offers many ways to orchestrate data quality checks directly from your DAGs.
This guide covers:
- Best practices and essential knowledge surrounding the planning of a data quality approach.
- When to implement data quality checks.
- How to choose a data quality check tool.
- How data lineage is connected to data quality.
- An in depth look at two commonly used data quality check tools: SQL Check operators and Great Expectations.
- An example comparing implementations of data quality checks using each of these tools.
Assumed knowledge
To get the most out of this guide, you should have knowledge of:
- What Airflow is and when to use it. See Introduction to Apache Airflow.
- Airflow operators. See Operators 101.
- Airflow connections. See Managing your Connections in Apache Airflow.
- Relational databases. See Relational database on Wikipedia.
Data quality essentials
What is considered good quality data is determined by the needs of your organization. Defining quality criteria for a given collection of datasets is often a task requiring collaboration with all data professionals involved in each step of the pipeline.
The following is a typical data quality check process:
- Assess where and in what formats relevant data is stored, and where it moves along your pipeline. A data lineage tool can assist with this process.
- Gather the data quality criteria from data professionals using the data.
- Determine the quality checks to run different components of the dataset.
- Determine where those quality checks should occur in your pipeline.
- Determine what happens when a check fails.
- Choose a data quality tool.
- Write the checks.
- Test the checks.
Types of data quality checks
Data quality checks can be run on different components of the dataset:
- Column: Common checks include confirming uniqueness of a key column, restricting the amount of
NULLvalues that are allowed, defining logical bounds for numeric or date columns, and defining valid options for categorical variables. - Row: Common checks include comparing the values in several columns for each row, and ensuring that there are no mutually exclusive values present in the same row.
- Table: Common checks include checking against a template schema to verify that it has not changed, and checking that a table has a minimum row count.
- Over several tables: Common checks include data parity checks across several tables. You can also create logical checks like making sure a customer marked as
inactivehas no purchases listed in any of the other tables.
It is also important to distinguish between the two types of control in data quality:
- Static control: Runs checks on Spark or Pandas dataframes, or on existing tables in a database. These checks can be performed anywhere in a typical ETL pipeline and might halt the pipeline in case of a failed check to prevent further processing of data with quality issues.
- Flow control: Monitors incoming data on a record-by-record basis, which sometimes prevents single records that fail certain data quality checks from entering the database. This guide does not cover flow controls.
Where to run data quality checks
Data quality checks can be run at different times within a data pipeline or an Airflow environment. It often makes sense to test them in a dedicated DAG before you incorporate them into your pipelines to make downstream behavior dependent on the outcome of selected data quality checks.
For example, data quality checks can be placed in the following locations within an ETL pipeline:
- Before the transform step (
data_quality_check_1) - After the transform step (
data_quality_check_2) - Branching off from a step (
data_quality_check_3)
The following DAG graph shows the typical locations for data quality checks:
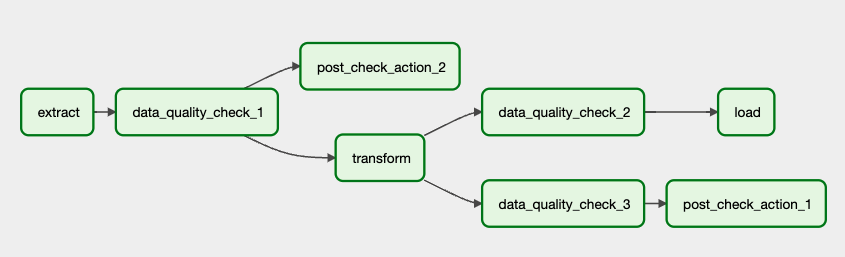
It's common to use the results of data quality checks (post_check_action_1 and post_check_action_2) to define further downstream tasks or callbacks. Typically, these tasks alert data professionals with error notifications, such as an email or a Slack message, of a data quality issue. It is also possible to create a downstream task that only runs when all data quality checks are successful. For example, the successful checking event for reporting purposes.
When implementing data quality checks, consider how a check success or failure should influence downstream dependencies. Trigger Rules are especially useful for managing operator dependencies.
When to implement data quality checks
When implementing data quality checks, it is important to consider the tradeoffs between the upfront work of implementing checks versus the cost of downstream issues caused by bad quality data.
You might need to implement data quality checks in the following circumstances:
- Downstream models serve customer-facing results that could be compromised in the case of a data quality issue.
- There are data quality concerns where an issue might not be immediately obvious to the data professional using the data.
Data quality tools
There are multiple open source tools that can be used to check data quality from an Airflow DAG. While this guide lists the most commonly used tools here, it focuses on the two tools that also integrate with OpenLineage:
- SQL Check operators: A group of operators that you can use to define data quality checks in Python dictionaries and SQL from within your DAGs.
- Great Expectations: An open source data validation framework where checks are defined in JSON. Airflow offers a provider package including the
GreatExpectationsOperatorfor easy integration.
Other tools that can be used for data quality checks include:
- Soda: An open source data validation framework that uses YAML to define checks which can be run in Airflow using the
BashOperator. Soda also offers the ability to write any custom checks using SQL. - dbt test: A testing framework for models using the
dbt testCLI command, which you can run in Airflow with theBashOperatororPythonOperator.
Choosing a tool
Which tool you choose is determined by the needs and preferences of your organization. Astronomer recommends using SQL Check operators if you want to:
- Write checks without needing to set up software in addition to Airflow.
- Write checks as Python dictionaries and in SQL.
- Use any SQL statement that returns a single row of booleans as a data quality check.
- Implement many different downstream dependencies depending on the outcome of different checks.
- Have full observability of which checks failed from within Airflow task logs, including the full SQL statements of failed checks.
Astronomer recommends using a data validation framework such as Great Expectations or Soda in the following circumstances:
- You want to collect the results of your data quality checks in a central place.
- You prefer to write checks in JSON (Great Expectations) or YAML (Soda).
- Most or all of your checks can be implemented by the predefined checks in the solution of your choice.
- You want to abstract your data quality checks from the DAG code.
Currently only SQL Check operators and the GreatExpectationsOperator offer data lineage extraction.
SQL Check operators
You can find more details and examples on SQL Check operators as well as example logs in the Airflow Data Quality Checks with SQL Operators guide.
SQL Check operators execute a SQL statement that results in a set of booleans. A result of True leads to the check passing and the task being labeled as successful. A result of False, or any error when the statement is executed, leads to a failure of the task. Before using any of the operators, you need to define the connection to your data storage from the Airflow UI or with an external secrets manager.
The SQL Check operators work with any backend solution that accepts SQL queries and supports Airflow, and differ in what kind of data quality checks they can perform and how they are defined.
The SQLColumnCheckOperator and SQLTableCheckOperator are part of the Common SQL provider. The other SQL Check operators are built into core Airflow and do not require separate package installation.
SQLColumnCheckOperator: Can quickly define checks on columns of a table using a Python dictionary.SQLTableCheckOperator: Can run aggregated and non-aggregated statements involving several columns of a table.SQLCheckOperator: Can be used with any SQL statement that returns a single row of booleans.SQLIntervalCheckOperator: Runs checks against historical data.SQLValueCheckOperator: Compares the result of a SQL query against a value with or without a tolerance window.SQLThresholdCheckOperator: Compares the result of a SQL query against upper and lower thresholds which may also be described as SQL queries.
The logs from SQL Check operators can be found in the regular Airflow task logs. For more details and examples of SQL Check operators and logs, see Airflow Data Quality Checks with SQL Operators.
Great Expectations
Great Expectations is an open source data validation framework that allows the user to define data quality checks as a JSON file. The checks, also known as Expectation Suites, can be run in a DAG using the GreatExpectationsOperator. All currently available expectations can be viewed on the Great Expectations website.
To use Great Expectations, you will need to install the open source Great Expectations package and set up a Great Expectations project with at least one instance of each of the following components:
- Data Context
- Datasource
- Expectation Suite
- Checkpoint
The Great Expectations documentation offers a step-by-step tutorial for this setup. Additionally, to use Great Expectations with Airflow, you have to install the Great Expectations provider package.
When using Great Expectations, Airflow task logs show only whether the Expectation Suite passed or failed. To get a detailed report on the checks that were run and their results, you can view the HTML files located in the great_expecations/uncommitted/data_docs/local_site/validations directory in any browser.
You can find more information on how to use Great Expectations with Airflow in the Integrating Airflow and Great Expectations guide.
Data lineage and data quality
In complex data ecosystems, lineage can be a powerful addition to data quality checks, especially for investigating what data from which origins caused a check to fail.
For more information on data lineage and setting up OpenLineage with Airflow, see OpenLineage and Airflow.
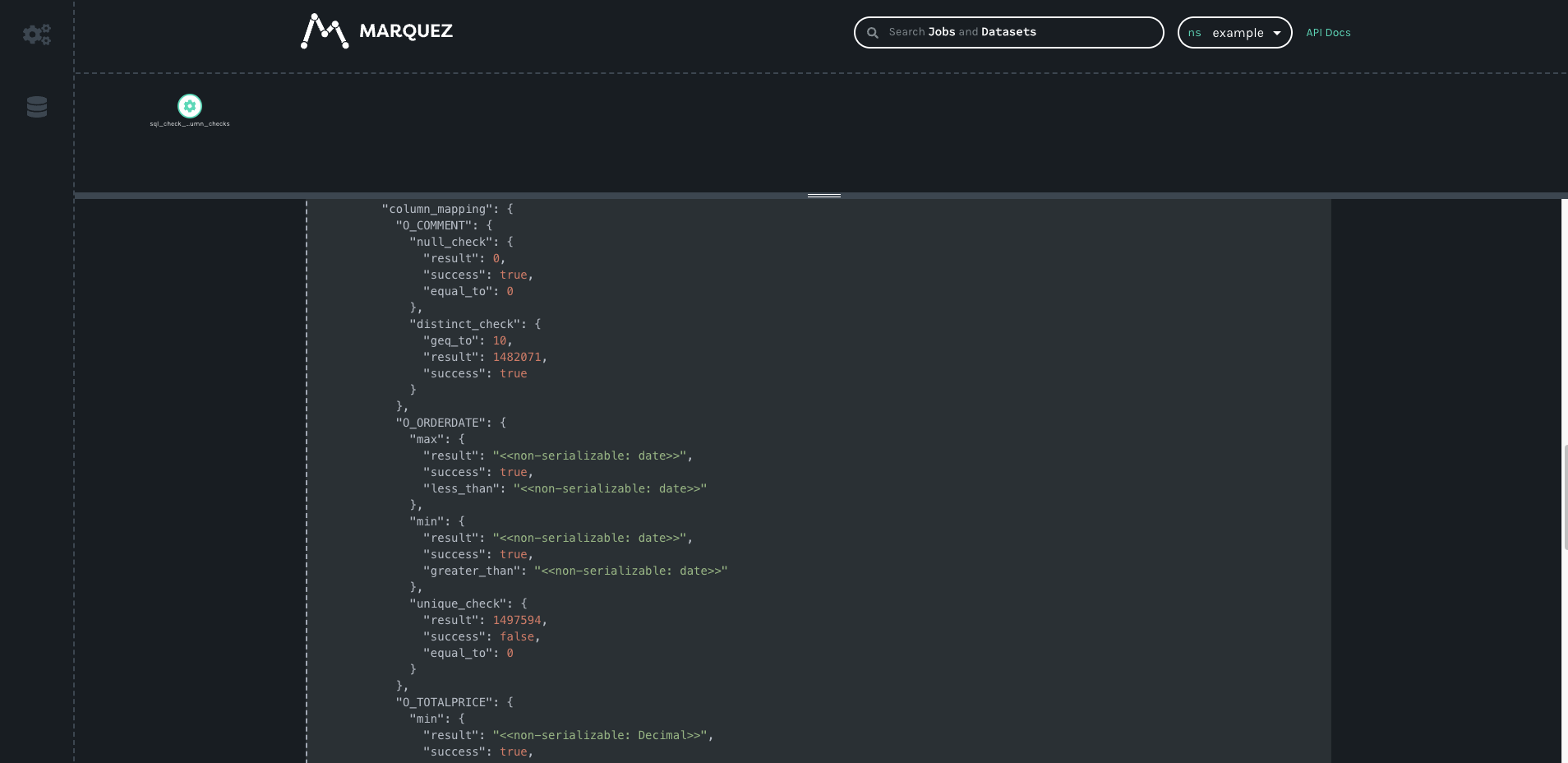
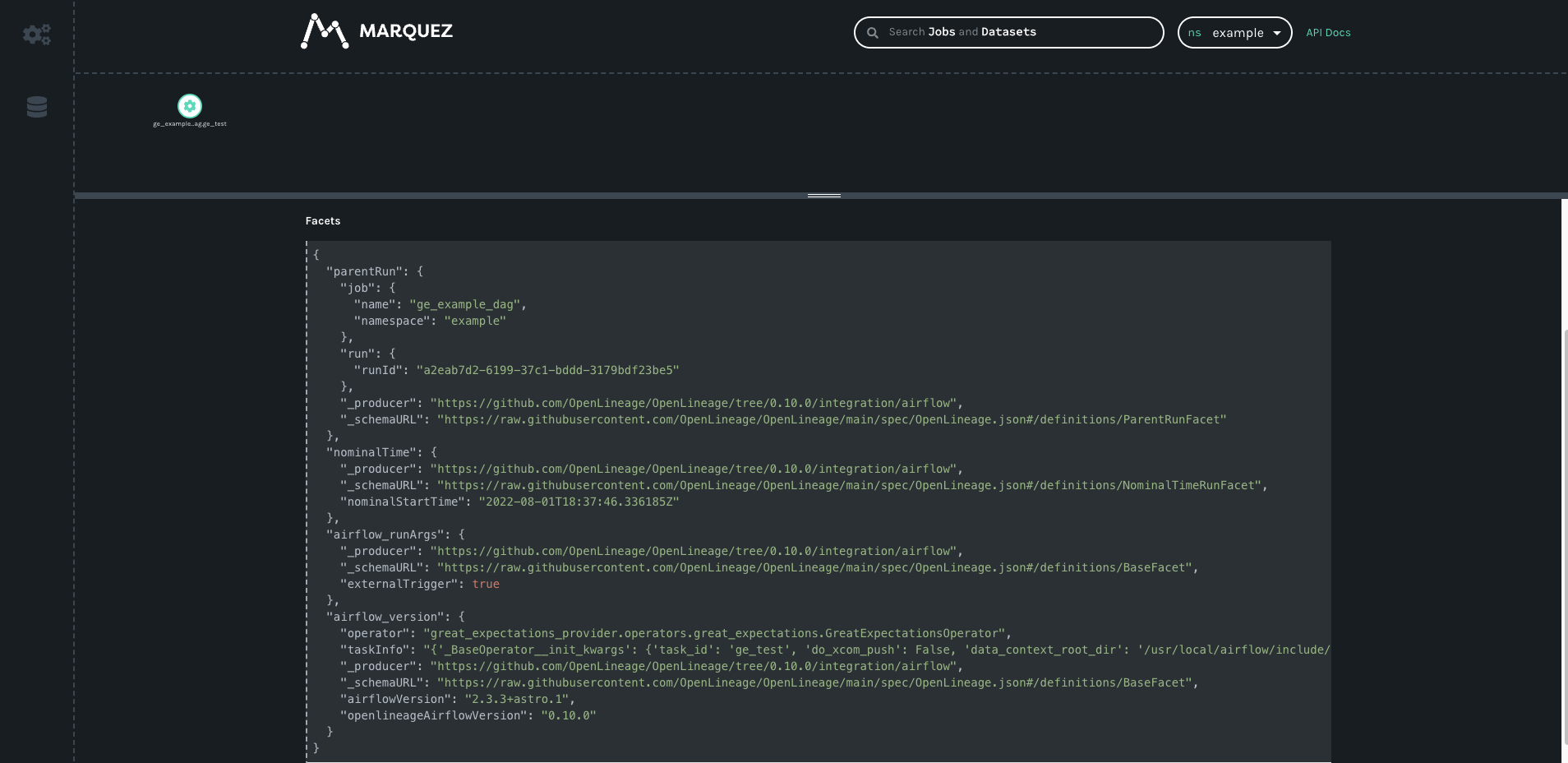
Both SQL Check operators and the GreatExpectationsOperator have OpenLineage extractors. If you are working with open source tools, you can view the resulting lineage from the extractors using Marquez.
The output from the SQLColumnCheckOperator contains each individual check and whether or not it succeeded:
For the GreatExpectationsOperator, OpenLineage receives whether or not the whole Expectation Suite succeeded or failed:
Example: Comparing SQL Check operators and Great Expectations
This example shows the steps necessary to perform the same set of data quality checks with SQL Check operators and with Great Expectations.
The checks performed for both tools are:
- "MY_DATE_COL" has only unique values.
- "MY_DATE_COL" has only values between 2017-01-01 and 2022-01-01.
- "MY_TEXT_COL" has no null values.
- "MY_TEXT_COL" has at least 10 distinct values.
- "MY_NUM_COL" has a minimum value between 90 and 110.
example_tablehas at least 1000 rows.- The value in each row of "MY_COL_1" plus the value of the same row in "MY_COL_2" is equal to 100.
- "MY_COL_3" contains only the values
val1,val2,val3andval4.
Example: SQL Check operators
The example DAG includes the following tasks:
- The
SQLColumnCheckOperatorperforms checks on several columns in the target table. - Two
SQLTableCheckOperatorsperform one check each. One operator checks several columns, while the other checks the entire table. - The
SQLCheckOperatormakes sure a categorical variable is set to one of four options.
While this example shows all the checks being written within the Python file defining the DAG, it is possible to modularize commonly used checks and SQL statements in separate files. If you're using the Astro CLI, you can add the files to the /include directory.
from airflow import DAG
from datetime import datetime
from airflow.operators.empty import EmptyOperator
from airflow.operators.sql import SQLCheckOperator
from airflow.providers.common.sql.operators.sql import (
SQLColumnCheckOperator, SQLTableCheckOperator
)
with DAG(
dag_id="example_dag_sql_check_operators",
schedule_interval='@daily',
start_date=datetime(2022, 7, 15),
catchup=False,
doc_md="""
Example DAG for SQL Check operators.
""",
default_args={
"conn_id": example_connection
}
) as dag:
start = EmptyOperator(task_id="start")
end = EmptyOperator(task_id="end")
# SQLColumnCheckOperator example: runs checks on 3 columns:
# - MY_DATE_COL is checked to only contain unique values ("unique_check")
# and to have dates greater than 2017-01-01 and lesser than 2022-01-01.
# - MY_TEXT_COL is checked to contain no NULL values
# and at least 10 distinct values
# - MY_NUM_COL is checked to have a minimum value between 90 and 110
column_checks = SQLColumnCheckOperator(
task_id="column_checks",
table=example_table,
column_mapping={
"MY_DATE_COL": {
"min": {"greater_than": datetime.date(2017, 1, 1)},
"max": {"less_than": datetime.date(2022, 1, 1)},
"unique_check": {"equal_to": 0}
},
"MY_TEXT_COL": {
"distinct_check": {"geq_to": 10},
"null_check": {"equal_to": 0}
},
"MY_NUM_COL": {
"max": {"equal_to": 100, "tolerance": 0.1}
},
}
)
# SQLTableCheckOperator example: This operator performs one check:
# - a row count check, making sure the table has >= 1000 rows
table_checks_aggregated = SQLTableCheckOperator(
task_id="table_checks_aggregated",
table=example_table,
checks={
"my_row_count_check": {
"check_statement": "COUNT(*) >= 1000"
}
}
)
# SQLTableCheckOperator example: This operator performs one check:
# - a columns comparison check to see that the value in MY_COL_1 plus
# the value in MY_COL_2 is 100
table_checks_not_aggregated = SQLTableCheckOperator(
task_id="table_checks_not_aggregated",
table=example_table,
checks={
"my_column_comparison_check": {
"check_statement": "MY_COL_1 + MY_COL_2 = 100"
}
}
)
# SQLCheckOperator example: ensure categorical values in MY_COL_3
# are one of a list of 4 options
check_val_in_list = SQLCheckOperator(
task_id="check_today_val_in_bounds",
conn_id=example_connection,
sql="""
WITH
not_in_list AS (
SELECT COUNT(*) as count_not_in_list
FROM {{ params.db_to_query }}.{{ params.schema }}.\
{{ params.table }}
WHERE {{ params.col }} NOT IN {{ params.options_tuple }}
)
SELECT
CASE WHEN count_not_in_list = 0 THEN 1
ELSE 0
END AS testresult
FROM not_in_list
""",
params={"db_to_query": example_database,
"schema": example_schema,
"table": example_table,
"col": "MY_COL_3",
"options_tuple": "('val1', 'val2', 'val3', 'val4')"
}
)
start >> [column_checks, table_checks_aggregated,
table_checks_not_aggregated, check_val_in_list] >> end
Example: Great Expectations
The following example runs the same data quality checks as the SQL Check operators example against the same database. After setting up the Great Expectations instance with all four components, the checks can be defined in a JSON file to form an Expectation Suite.
For each of the checks in this example, an Expectation Suite already exists. This is not always the case, and for more complicated checks you may need to define a custom Expectation Suite.
{
"data_asset_type": null,
"expectation_suite_name": "my_suite",
"expectations": [
{
"expectation_context": {
"description": "MY_DATE_COL has values between 2017-01-01 - 2022-01-01"
},
"expectation_type": "expect_column_values_to_be_between",
"ge_cloud_id": null,
"kwargs": {
"column": "MY_DATE_COL",
"max_value": "2022-01-01",
"min_value": "2017-01-01"
},
"meta": {}
},
{
"expectation_context": {
"description": "MY_DATE_COL's values are all unique"
},
"expectation_type": "expect_column_values_to_be_unique",
"ge_cloud_id": null,
"kwargs": {
"column": "MY_DATE_COL"
},
"meta": {}
},
{
"expectation_context": {
"description": "MY_TEXT_COL has at least 10 distinct values"
},
"expectation_type": "expect_column_unique_value_count_to_be_between",
"ge_cloud_id": null,
"kwargs": {
"column": "MY_TEXT_COL",
"min_value": 10
},
"meta": {}
},
{
"expectation_context": {
"description": "MY_TEXT_COL has no NULL values"
},
"expectation_type": "expect_column_values_to_not_be_null",
"ge_cloud_id": null,
"kwargs": {
"column": "MY_TEXT_COL"
},
"meta": {}
},
{
"expectation_context": {
"description": "MY_NUM_COL has a maximum val between 90 and 110"
},
"expectation_type": "expect_column_max_to_be_between",
"ge_cloud_id": null,
"kwargs": {
"column": "MY_NUM_COL",
"min_value": 90,
"max_value": 110
},
"meta": {}
},
{
"expectation_context": {
"description": "the table has at least 1000 rows"
},
"expectation_type": "expect_table_row_count_to_be_between",
"ge_cloud_id": null,
"kwargs": {
"min_value": 1000
},
"meta": {}
},
{
"expectation_context": {
"description": "for each row MY_COL_1 plus MY_COL_2 is = 100"
},
"expectation_type": "expect_multicolumn_sum_to_equal",
"ge_cloud_id": null,
"kwargs": {
"column_list": ["MY_COL_1", "MY_COL_2"],
"sum_total": 100
},
"meta": {}
},
{
"expectation_context": {
"description": "MY_COL_3 only contains values from a defined set"
},
"expectation_type": "expect_column_values_to_be_in_set",
"ge_cloud_id": null,
"kwargs": {
"column": "MY_COL_3",
"value_set": ["val1", "val2", "val3", "val4"]
},
"meta": {}
}
],
"ge_cloud_id": null,
"meta": {
"great_expectations_version": "0.15.14"
}
}
The corresponding DAG code shows how all checks are run within one task using the GreatExpectationsOperator. Only the root directory of the data context and the checkpoint name have to be provided. To use XComs with the GreatExpectationsOperator you must enable XCOM pickling as described in the Great Expectations guide.
from airflow import DAG
from datetime import datetime
from great_expectations_provider.operators.great_expectations import (
GreatExpectationsOperator
)
with DAG(
schedule_interval=None,
start_date=datetime(2022,7,1),
dag_id="ge_example_dag",
catchup=False,
) as dag:
# task running the Expectation Suite defined in the JSON above
ge_test = GreatExpectationsOperator(
task_id="ge_test",
data_context_root_dir="/usr/local/airflow/include/great_expectations",
checkpoint_name="my_checkpoint",
do_xcom_push=False
)
Conclusion
The growth of tools designed to perform data quality checks reflect the importance of ensuring data quality in production workflows. Commitment to data quality requires in-depth planning and collaboration between data professionals. What kind of data quality your organization needs will depend on your unique use case, which you can explore using the steps outlined in this guide. Special consideration should be given to the type of data quality checks and their location in the data pipeline.
Integrating Airflow with a data lineage tool can further enhance your ability to trace the origin of data that did not pass the checks you established.
This guide highlights two data quality tools and their use cases:
- SQL Check operators offer a way to define your checks directly from within the DAG, with no other tools necessary.
- If you run many checks on different databases, you may benefit from using a more complex testing solution like Great Expectations or Soda.
No matter which tool is used, data quality checks can be orchestrated from within an Airflow DAG, which makes it possible to trigger downstream actions depending on the outcome of your checks.