Manage DAG and task dependencies in Airflow
Dependencies are a powerful and popular Airflow feature. In Airflow, your pipelines are defined as Directed Acyclic Graphs (DAGs). Each task is a node in the graph and dependencies are the directed edges that determine how to move through the graph. Because of this, dependencies are key to following data engineering best practices because they help you define flexible pipelines with atomic tasks.
Throughout this guide, the following terms are used to describe task dependencies:
- Upstream task: A task that must reach a specified state before a dependent task can run.
- Downstream task: A dependent task that cannot run until an upstream task reaches a specified state.
In this guide you'll learn about the many ways you can implement dependencies in Airflow, including:
- Basic task dependencies.
- Dynamic dependencies.
- Dependencies with task groups.
- Dependencies with the TaskFlow API.
- Trigger rules.
To view a video presentation of these concepts, see Manage Dependencies Between Airflow Deployments, DAGs, and Tasks.
The focus of this guide is dependencies between tasks in the same DAG. If you need to implement dependencies between DAGs, see Cross-DAG dependencies.
Assumed knowledge
To get the most out of this guide, you should have an understanding of:
- Basic Airflow concepts. See Introduction to Apache Airflow.
Basic dependencies
Basic dependencies between Airflow tasks can be set in the following ways:
- Using bitshift operators (
<<and>>) - Using the
set_upstreamandset_downstreammethods
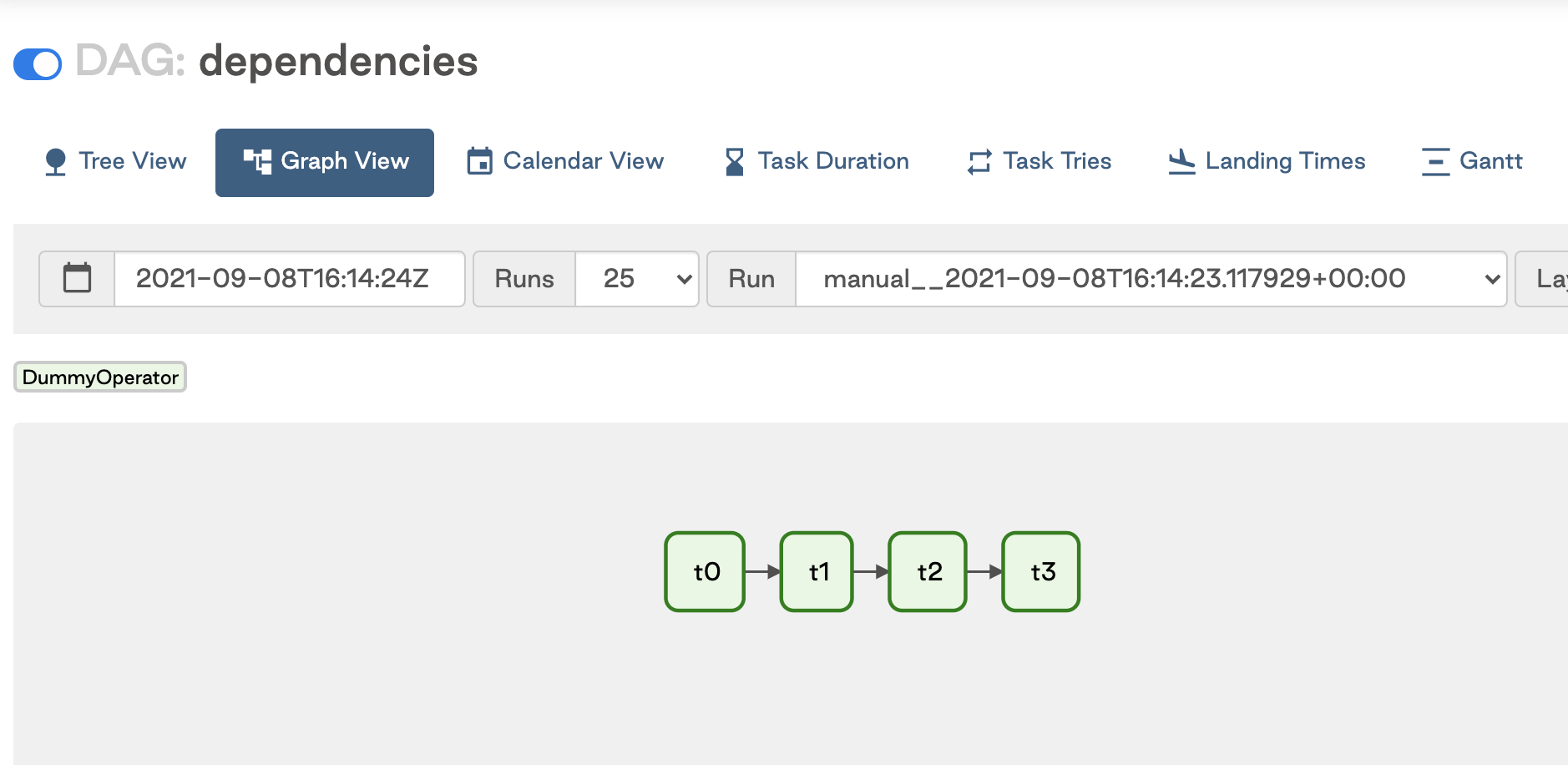
For example, if you have a DAG with four sequential tasks, the dependencies can be set in four ways:
Using
set_downstream():t0.set_downstream(t1)
t1.set_downstream(t2)
t2.set_downstream(t3)Using
set_upstream():t3.set_upstream(t2)
t2.set_upstream(t1)
t1.set_upstream(t0)Using
>>t0 >> t1 >> t2 >> t3Using
<<t3 << t2 << t1 << t0
All of these methods are equivalent and result in the DAG shown in the following image:
Astronomer recommends using a single method consistently. Using both bitshift operators and set_upstream/set_downstream in your DAGs can overly-complicate your code.
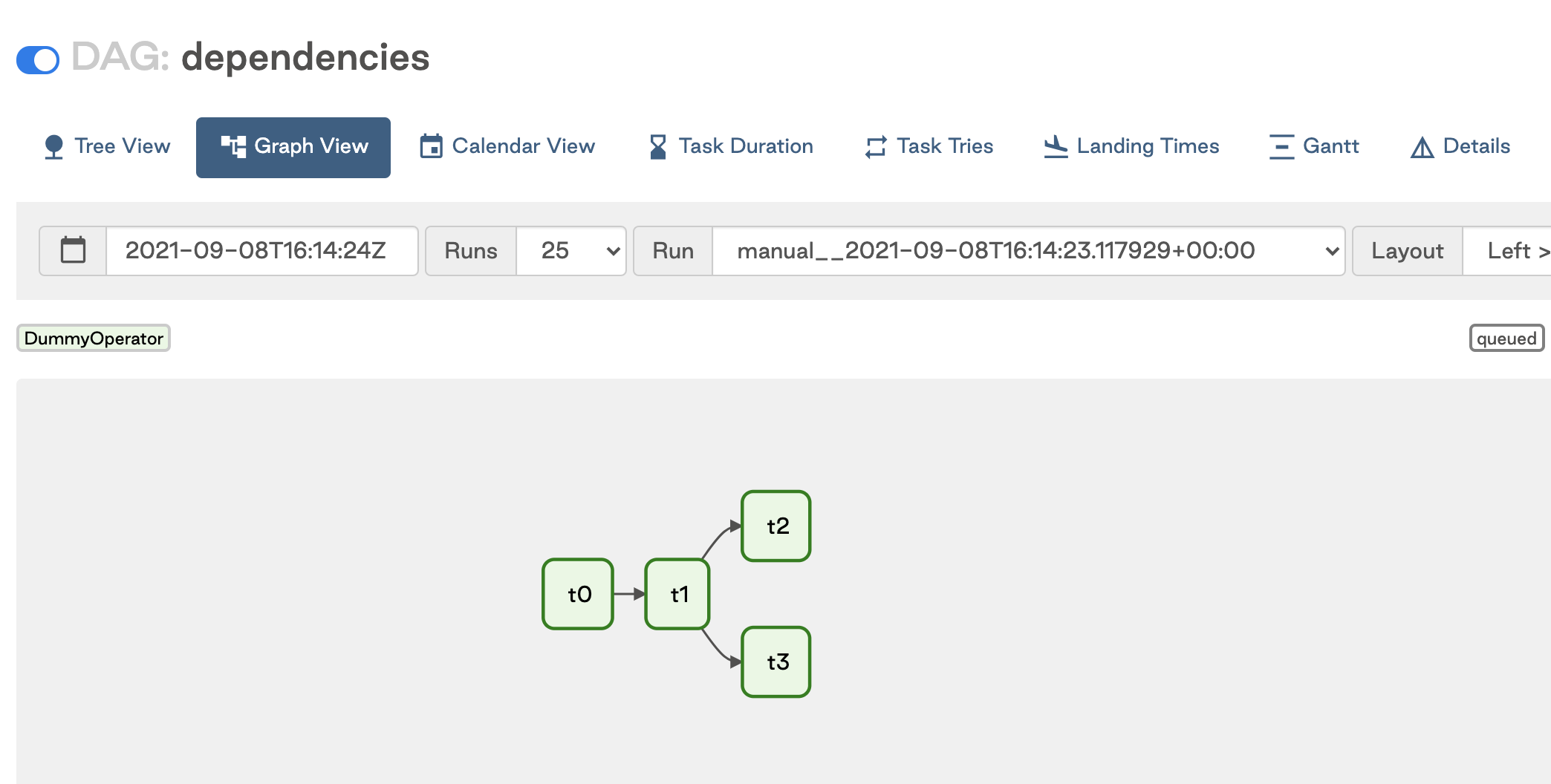
To set a dependency where two downstream tasks are dependent on the same upstream task, use lists or tuples. For example:
# Dependencies with lists
t0 >> t1 >> [t2, t3]
# Dependencies with tuples
t0 >> t1 >> (t2, t3)
These statements are equivalent and result in the DAG shown in the following image:
Airflow can't parse dependencies between two lists. For example, [t0, t1] >> [t2, t3] returns an error. To set these dependencies, use the Airflow chain function. For example:
from airflow import DAG
from airflow.operators.empty import EmptyOperator
from airflow.models.baseoperator import chain
with DAG('dependencies',
) as dag:
t0 = EmptyOperator(task_id='t0')
t1 = EmptyOperator(task_id='t1')
t2 = EmptyOperator(task_id='t2')
t3 = EmptyOperator(task_id='t3')
t4 = EmptyOperator(task_id='t4')
t5 = EmptyOperator(task_id='t5')
t6 = EmptyOperator(task_id='t6')
chain(t0, t1, [t2, t3], [t4, t5], t6)
This image shows the resulting DAG:
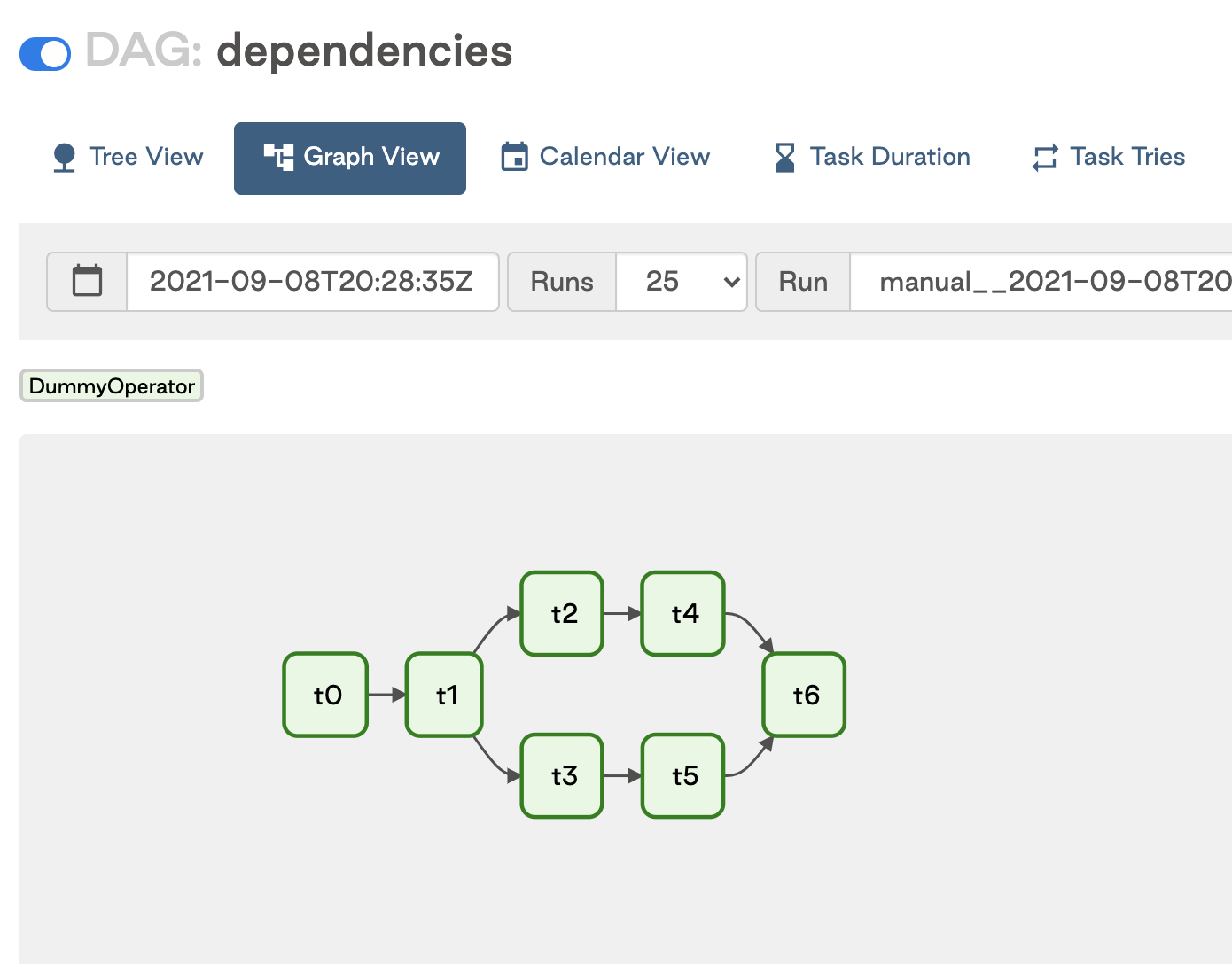
With the chain function, any lists or tuples you include must be of the same length.
Dynamic dependencies
If you generate tasks dynamically in your DAG, you should define the dependencies within the context of the code used to dynamically create the tasks.
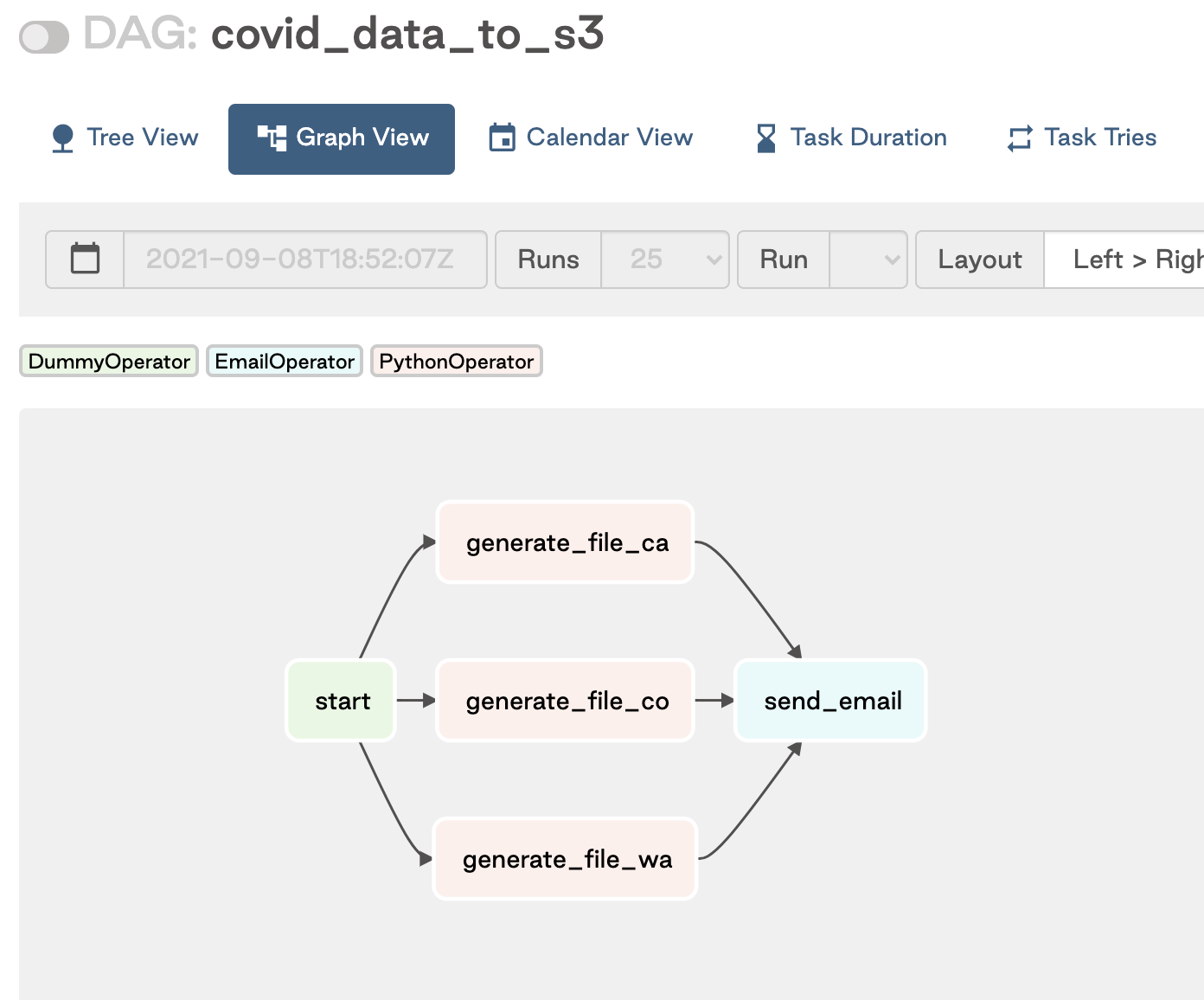
In the following example, a set of parallel dynamic tasks is generated by looping through a list of endpoints. Each generate_files task is downstream of start and upstream of send_email.
with DAG('covid_data_to_s3') as dag:
t0 = EmptyOperator(task_id='start')
send_email = EmailOperator(
task_id='send_email',
to=email_to,
subject='Covid to S3 DAG',
html_content='<p>The Covid to S3 DAG completed successfully. Files can now be found on S3. <p>'
)
for endpoint in endpoints:
generate_files = PythonOperator(
task_id='generate_file_{0}'.format(endpoint),
python_callable=upload_to_s3,
op_kwargs={'endpoint': endpoint, 'date': date}
)
t0 >> generate_files >> send_email
This image shows the resulting DAG:
Task group dependencies
Task groups are a UI-based grouping concept available in Airflow 2.0 and later. For more information on task groups, including how to create them and when to use them, see Using Task Groups in Airflow.
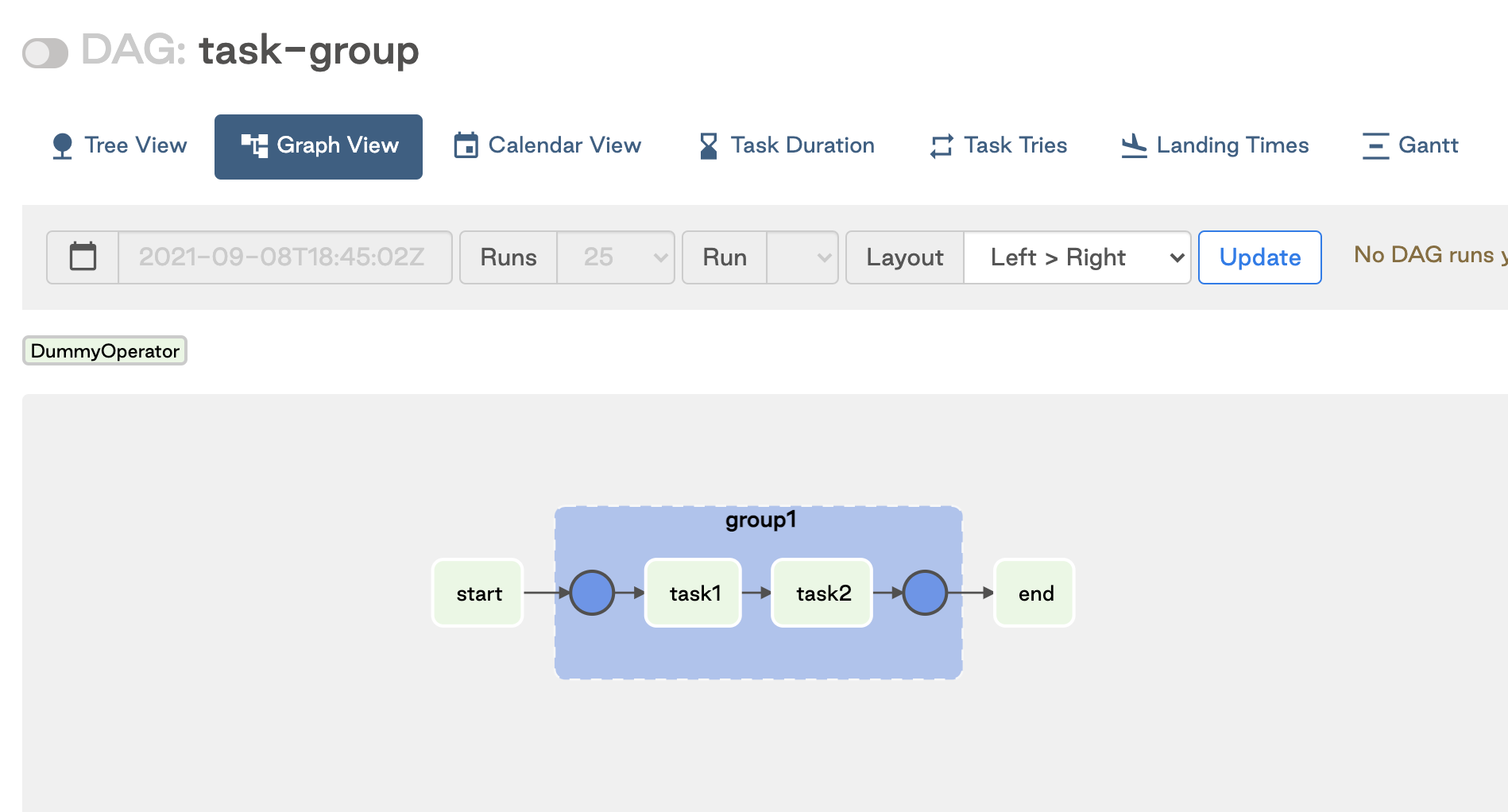
When working with task groups, it is important to note that dependencies can be set both inside and outside of the group. For example, in the following DAG code there is a start task, a task group with two dependent tasks, and an end task that needs to happen sequentially. The dependencies between the two tasks in the task group are set within the task group's context (t1 >> t2). The dependencies between the task group and the start and end tasks are set within the DAG's context (t0 >> tg1 >> t3).
t0 = EmptyOperator(task_id='start')
# Start Task Group definition
with TaskGroup(group_id='group1') as tg1:
t1 = EmptyOperator(task_id='task1')
t2 = EmptyOperator(task_id='task2')
t1 >> t2
# End Task Group definition
t3 = EmptyOperator(task_id='end')
# Set Task Group's (tg1) dependencies
t0 >> tg1 >> t3
This image shows the resulting DAG:
TaskFlow API dependencies
The TaskFlow API, available in Airflow 2.0 and later, lets you turn Python functions into Airflow tasks using the @task decorator.
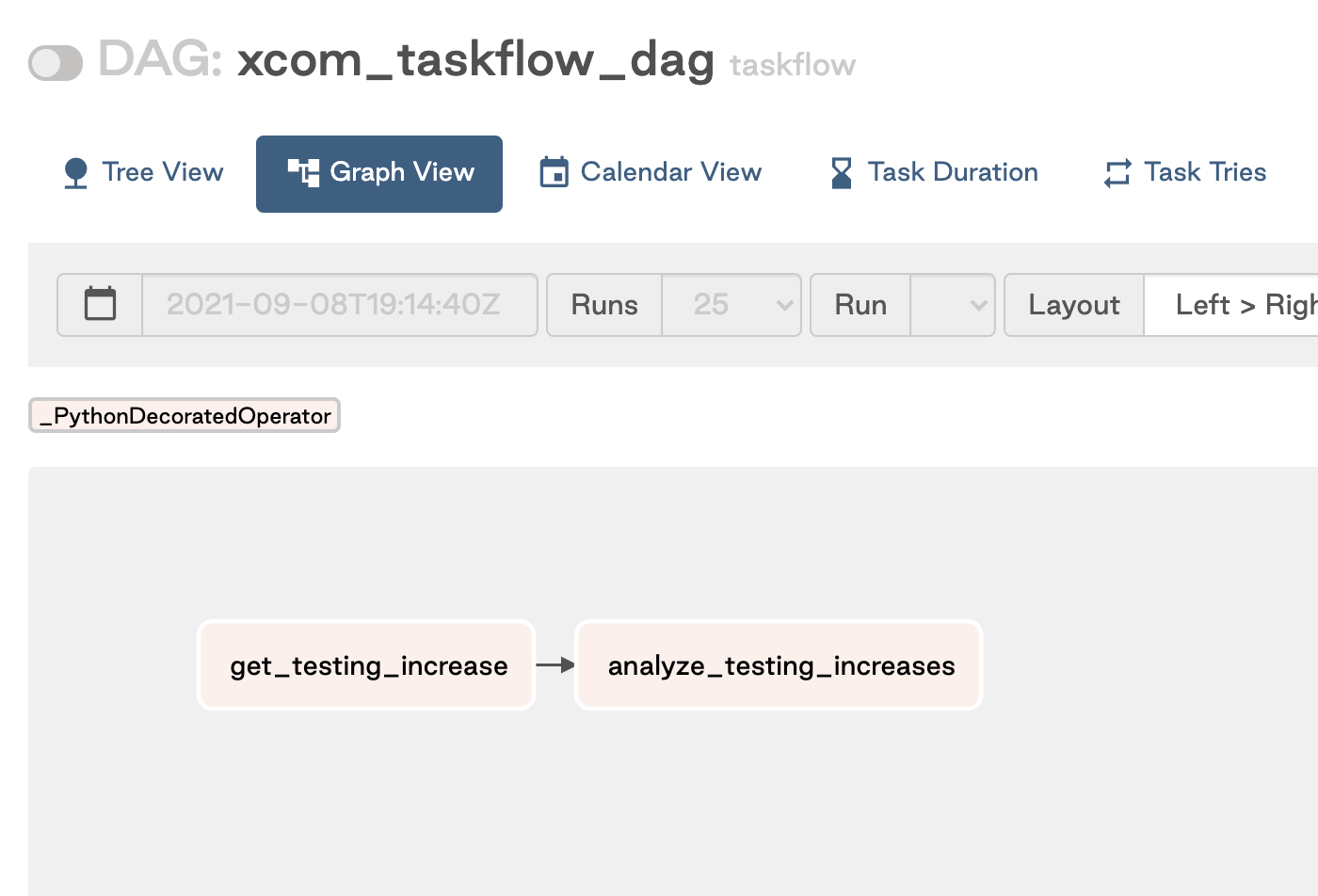
If your DAG has only Python functions that are all defined with the decorator, invoke Python functions to set dependencies. For example, in the following DAG there are two dependent tasks, get_testing_increases and analyze_testing_increases. To set the dependencies, you invoke the function analyze_testing_increases(get_testing_increase(state)):
from airflow.decorators import dag, task
from datetime import datetime
import requests
import json
url = 'https://covidtracking.com/api/v1/states/'
state = 'wa'
default_args = {
'start_date': datetime(2021, 1, 1)
}
@dag('xcom_taskflow_dag', schedule_interval='@daily', default_args=default_args, catchup=False)
def taskflow():
@task
def get_testing_increase(state):
"""
Gets totalTestResultsIncrease field from Covid API for given state and returns value
"""
res = requests.get(url+'{0}/current.json'.format(state))
return{'testing_increase': json.loads(res.text)['totalTestResultsIncrease']}
@task
def analyze_testing_increases(testing_increase: int):
"""
Evaluates testing increase results
"""
print('Testing increases for {0}:'.format(state), testing_increase)
#run some analysis here
# Invoke functions to create tasks and define dependencies
analyze_testing_increases(get_testing_increase(state))
dag = taskflow()
This image shows the resulting DAG:
If your DAG has a mix of Python function tasks defined with decorators and tasks defined with traditional operators, you can set the dependencies by assigning the decorated task invocation to a variable and then defining the dependencies normally. For example, in the DAG below the upload_data_to_s3 task is defined by the @task decorator and invoked with upload_data = upload_data_to_s3(s3_bucket, test_s3_key). The upload_data variable is used in the last line to define dependencies.
with DAG('sagemaker_model',
) as dag:
@task
def upload_data_to_s3(s3_bucket, test_s3_key):
"""
Uploads validation data to S3 from /include/data
"""
s3_hook = S3Hook(aws_conn_id='aws-sagemaker')
# Take string, upload to S3 using predefined method
s3_hook.load_file(filename='include/data/test.csv',
key=test_s3_key,
bucket_name=s3_bucket,
replace=True)
upload_data = upload_data_to_s3(s3_bucket, test_s3_key)
predict = SageMakerTransformOperator(
task_id='predict',
config=transform_config,
aws_conn_id='aws-sagemaker'
)
results_to_redshift = S3ToRedshiftOperator(
task_id='save_results',
aws_conn_id='aws-sagemaker',
s3_bucket=s3_bucket,
s3_key=output_s3_key,
schema="PUBLIC",
table="results",
copy_options=['csv'],
)
upload_data >> predict >> results_to_redshift
Trigger rules
When you set dependencies between tasks, the default Airflow behavior is to run a task only when all upstream tasks have succeeded. You can use trigger rules to change this default behavior.
The following options are available:
- all_success: (default) The task runs only when all upstream tasks have succeeded.
- all_failed: The task runs only when all upstream tasks are in a failed or upstream_failed state.
- all_done: The task runs once all upstream tasks are done with their execution.
- all_skipped: The task runs only when all upstream tasks have been skipped.
- one_failed: The task runs as soon as at least one upstream task has failed.
- one_success: The task runs as soon as at least one upstream task has succeeded.
- none_failed: The task runs only when all upstream tasks have succeeded or been skipped.
- none_failed_min_one_success: The task runs only when all upstream tasks have not failed or upstream_failed, and at least one upstream task has succeeded.
- none_skipped: The task runs only when no upstream task is in a skipped state.
- always: The task runs at any time.
Branching and trigger rules
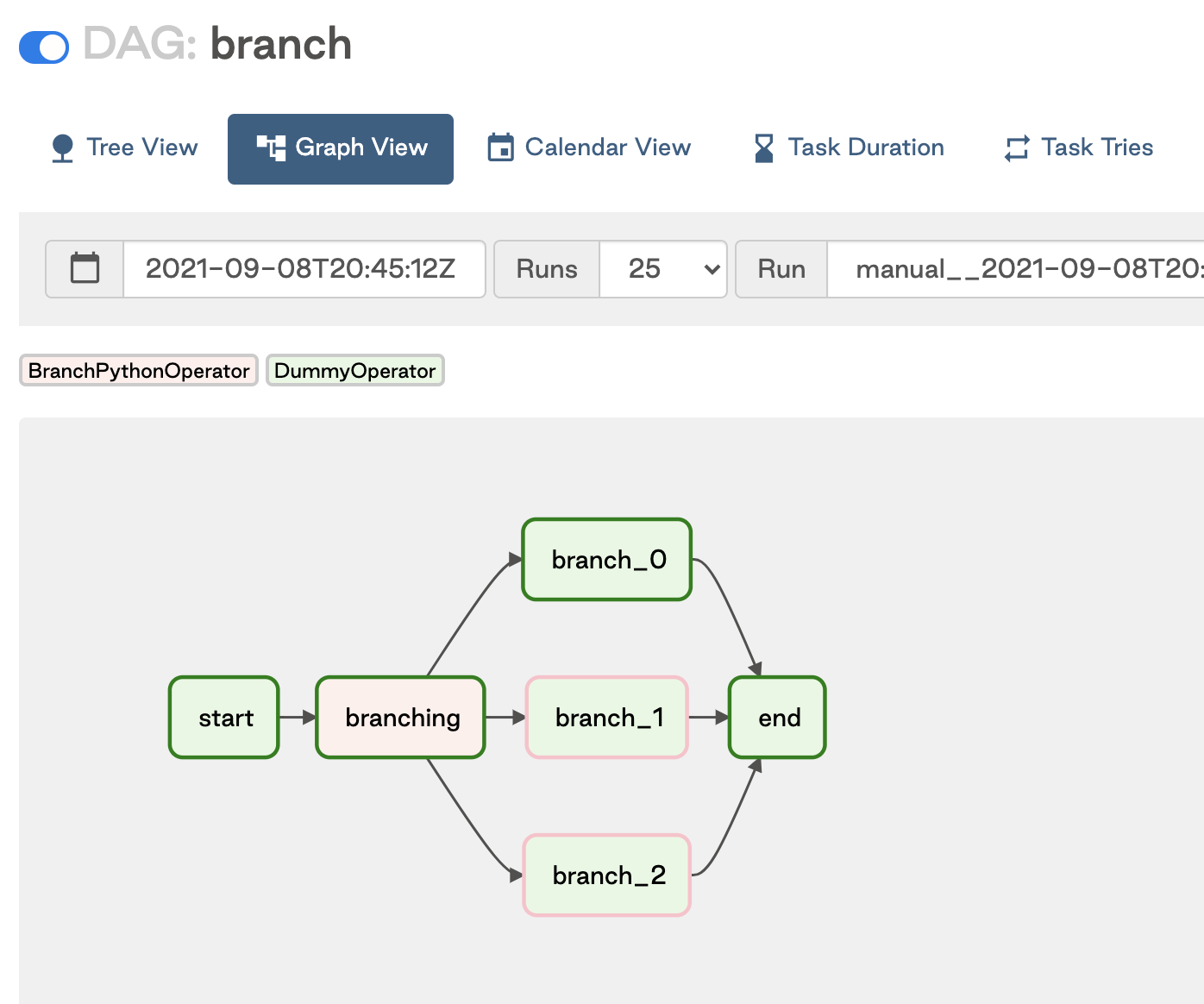
One common scenario where you might need to implement trigger rules is if your DAG contains conditional logic such as branching. In these cases, one_success might be a more appropriate rule than all_success.
In the following example DAG there is a simple branch with a downstream task that needs to run if either of the branches are followed. With the all_success rule, the end task never runs because all but one of the branch tasks is always ignored and therefore doesn't have a success state. If you change the trigger rule to one_success, then the end task can run so long as one of the branches successfully completes.
import random
from airflow import DAG
from airflow.operators.empty import EmptyOperator
from airflow.operators.python import BranchPythonOperator
from datetime import datetime
from airflow.utils.trigger_rule import TriggerRule
def return_branch(**kwargs):
branches = ['branch_0', 'branch_1', 'branch_2']
return random.choice(branches)
with DAG(dag_id='branch',
start_date=datetime(2021, 1, 1),
max_active_runs=1,
schedule_interval=None,
catchup=False
) as dag:
#EmptyOperators
start = EmptyOperator(task_id='start')
end = EmptyOperator(
task_id='end',
trigger_rule=TriggerRule.ONE_SUCCESS
)
branching = BranchPythonOperator(
task_id='branching',
python_callable=return_branch,
provide_context=True
)
start >> branching
for i in range(0, 3):
d = EmptyOperator(task_id='branch_{0}'.format(i))
branching >> d >> end
This image shows the resulting DAG: