Integrate OpenLineage and Airflow
Data lineage is the concept of tracking and visualizing data from its origin to wherever it flows and is consumed downstream. Its prominence in the data space is growing rapidly as companies have increasingly complex data ecosystems alongside increasing reliance on accurate data for making business decisions. Data lineage can help with everything from understanding your data sources, to troubleshooting job failures, to managing PII, to ensuring compliance with data regulations.
It follows that data lineage has a natural integration with Apache Airflow. Airflow is often used as a one-stop-shop orchestrator for an organization’s data pipelines, which makes it an ideal platform for integrating data lineage to understand the movement and interactions of your data.
In this tutorial, you’ll define data lineage, review the OpenLineage standard and core lineage concepts, describe why you would want data lineage with Airflow, and implement an example local integration of Airflow and OpenLineage for tracking data movement in Postgres.
This guide focuses on using OpenLineage with Airflow 2. Some topics may differ if you are using it with earlier versions of Airflow.
Assumed knowledge
To get the most out of this tutorial, make sure you have an understanding of:
- Airflow fundamentals, such as writing DAGs and defining tasks. See Get started with Apache Airflow.
- Airflow operators. See Operators 101.
What is data lineage
Data lineage is a way of tracing the complex set of relationships that exist among datasets within an ecosystem. The concept of data lineage encompasses:
- Lineage metadata - describes your datasets (a table in Snowflake, for example) and jobs (tasks in your DAG, for example).
- A Lineage backend - stores and processes lineage metadata.
- A lineage frontend - allows you to view and interact with your lineage metadata, including a graph that visualizes your jobs and datasets and shows how they are connected.
If you want to read more on the concept of data lineage and why it’s important, see this Astronomer blog post.
Visually, your data lineage graph might look similar to this:
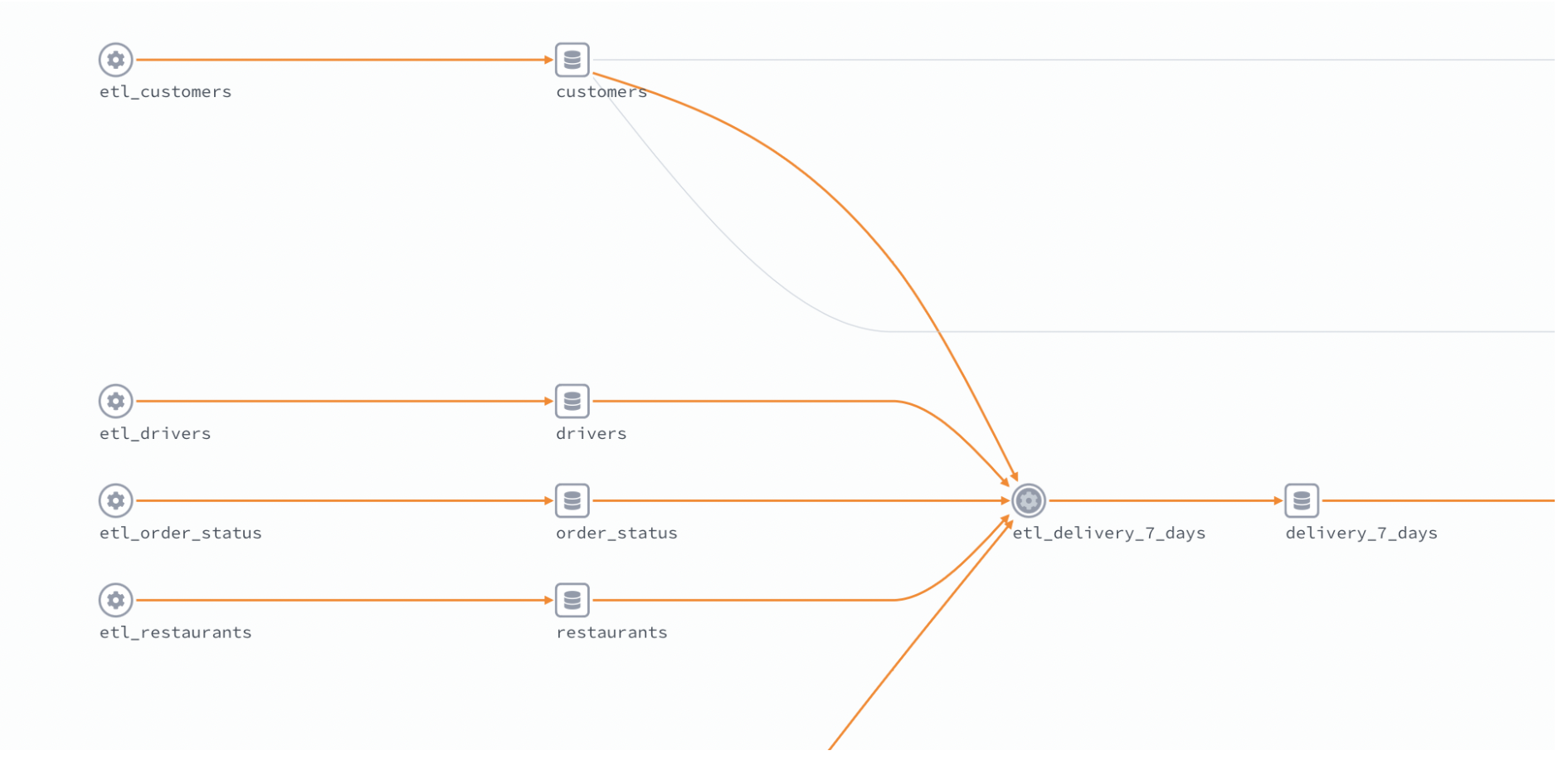
If you are using data lineage, you will likely have a lineage tool that collects lineage metadata, as well as a front end for visualizing the lineage graph. There are paid tools (including Astro) that provide these services, but in this guide the focus is on the open source options that can be integrated with Airflow: namely OpenLineage (the lineage tool) and Marquez (the lineage front end).
OpenLineage
OpenLineage is the open source industry standard framework for data lineage. It standardizes the definition of data lineage, the metadata that makes up lineage data, and the approach for collecting lineage data from external systems. In other words, it defines a formalized specification for all of the core concepts related to data lineage.
The purpose of a standard like OpenLineage is to create a more cohesive lineage experience across the industry and reduce duplicated work for stakeholders. It allows for a simpler, more consistent experience when integrating lineage with many different tools, similar to how Airflow providers reduce the work of DAG authoring by providing standardized modules for integrating Airflow with other tools.
If you are working with lineage data from Airflow, the integration is built from OpenLineage using the openlineage-airflow package. You can read more about that integration in the OpenLineage documentation.
Core concepts
The following terms are used frequently when discussing data lineage and OpenLineage in particular:
- Integration: A means of gathering lineage data from a source system such as a scheduler or data platform. For example, the OpenLineage Airflow integration allows lineage data to be collected from Airflow DAGs. Existing integrations automatically gather lineage data from the source system every time a job runs, preparing and transmitting OpenLineage events to a lineage backend. A full list of OpenLineage integrations can be found here.
- Extractor: An extractor is a module that gathers lineage metadata from a specific hook or operator. For example, in the
openlineage-airflowpackage, extractors exist for thePostgresOperatorandSnowflakeOperator, meaning that ifopenlineage-airflowis installed and running in your Airflow environment, lineage data will be generated automatically from those operators when your DAG runs. An extractor must exist for a specific operator to get lineage data from it. - Job: A process which consumes or produces datasets. Jobs can be viewed on your lineage graph. In the context of the Airflow integration, an OpenLineage job corresponds to a task in your DAG. Note that only tasks that come from operators with extractors will have input and output metadata; other tasks in your DAG will show as orphaned on the lineage graph.
- Dataset: A representation of a set of data in your lineage data and graph. For example, it might correspond to a table in your database or a set of data you run a Great Expectations check on. Typically a dataset is registered as part of your lineage data when a job writing to the dataset is completed (e.g. data is inserted into a table).
- Run: An instance of a job where lineage data is generated. In the context of the Airflow integration, an OpenLineage run will be generated with each DAG run.
- Facet: A piece of lineage metadata about a job, dataset, or run (e.g. you might hear “job facet”).
Why OpenLineage with Airflow?
In the previous section above, you learned what lineage is, but a question remains why you would want to have data lineage in conjunction with Airflow. Using OpenLineage with Airflow allows you to have more insight into complex data ecosystems and can lead to better data governance. Airflow is a natural place to integrate data lineage, because it is often used as a one-stop-shop orchestrator that touches data across many parts of an organization.
More specifically, OpenLineage with Airflow provides the following capabilities:
- Quickly find the root cause of task failures by identifying issues in upstream datasets (e.g. if an upstream job outside of Airflow failed to populate a key dataset).
- Easily see the blast radius of any job failures or changes to data by visualizing the relationship between jobs and datasets.
- Identify where key data is used in jobs across an organization.
These capabilities translate into real world benefits by:
- Making recovery from complex failures quicker. The faster you can identify the problem and the blast radius, the easier it is to solve and prevent any erroneous decisions being made from bad data.
- Making it easier for teams to work together across an organization. Visualizing the full scope of where a dataset is used reduces “sleuthing” time.
- Helping ensure compliance with data regulations by fully understanding where data is used.
Example OSS integration
In this example, you'll learn how to run OpenLineage with Airflow locally using Marquez as a lineage front end. You'll then learn how to use and interpret the lineage data generated by a simple DAG that processes data in Postgres. All of the tools used in this example are open source.
Running Marquez and Airflow locally
For this example, you’ll run Airflow with OpenLineage and Marquez locally. You will need to install Docker and the Astro CLI before starting.
Run Marquez locally using the quickstart in the Marquez README.
Start an Astro project using the CLI by creating a new directory and running
astro dev init. In this example the directory name isopenlineage.Add
openlineage-airflowto yourrequirements.txtfile. If you are using Astro Runtime 4.2.1 or greater, this package is already included.Add the environment variables below to your
.envfile to allow Airflow to connect with the OpenLineage API and send your lineage data to Marquez.OPENLINEAGE_URL=http://host.docker.internal:5000
OPENLINEAGE_NAMESPACE=example
AIRFLOW__LINEAGE__BACKEND=openlineage.lineage_backend.OpenLineageBackendBy default, Marquez uses port 5000 when you run it using Docker. If you are using a different OpenLineage front end instead of Marquez, or you are running Marquez remotely, you can modify the
OPENLINEAGE_URLas needed.Modify your
config.yamlin the.astro/directory to choose a different port for Postgres. Marquez also uses Postgres, so you will need to have Airflow use a different port than the default 5432, which is already allocated.project:
name: openlineage
postgres:
port: 5435Run
astro dev startto run Airflow locally.Confirm Airflow is running by going to
http://localhost:8080, and Marquez is running by going tohttp://localhost:3000.
Generate and view lineage data
To show the lineage data that can result from Airflow DAG runs, you'll use two sample DAGs that process data in Postgres. To run this example in your own environment, complete the following steps:
Ensure you have a running Postgres database (separate from the Airflow and Marquez metastores). If you are working with the Astro CLI, you can create a database locally in the same container as the Airflow metastore using
psql:psql -h localhost -p 5435 -U postgres
<enter password `postgres` when prompted>
create database lineagedemo;Create and populate two source tables that will be used in the example DAGs below. You can alternatively update the table names and schemas in the DAG to reference existing tables in your own environment. To use the given example DAGs, run the following queries:
CREATE TABLE IF NOT EXISTS adoption_center_1
(date DATE, type VARCHAR, name VARCHAR, age INTEGER);
CREATE TABLE IF NOT EXISTS adoption_center_2
(date DATE, type VARCHAR, name VARCHAR, age INTEGER);
INSERT INTO
adoption_center_1 (date, type, name, age)
VALUES
('2022-01-01', 'Dog', 'Bingo', 4),
('2022-02-02', 'Cat', 'Bob', 7),
('2022-03-04', 'Fish', 'Bubbles', 2);
INSERT INTO
adoption_center_2 (date, type, name, age)
VALUES
('2022-06-10', 'Horse', 'Seabiscuit', 4),
('2022-07-15', 'Snake', 'Stripes', 8),
('2022-08-07', 'Rabbit', 'Hops', 3);Create an Airflow connection to the Postgres database you created in Step 1.
With those prerequisites met, you can move on to the example DAGs. The first DAG creates and populates a table (animal_adoptions_combined) with data aggregated from the two source tables (adoption_center_1 and adoption_center_2). You might want to make adjustments to this DAG if you are working with different source tables, or if your Postgres connection id is not postgres_default.
from airflow import DAG
from airflow.providers.postgres.operators.postgres import PostgresOperator
from datetime import datetime, timedelta
create_table_query= '''
CREATE TABLE IF NOT EXISTS animal_adoptions_combined (date DATE, type VARCHAR, name VARCHAR, age INTEGER);
'''
combine_data_query= '''
INSERT INTO animal_adoptions_combined (date, type, name, age)
SELECT *
FROM adoption_center_1
UNION
SELECT *
FROM adoption_center_2;
'''
with DAG('lineage-combine-postgres',
start_date=datetime(2020, 6, 1),
max_active_runs=1,
schedule_interval='@daily',
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=1)
},
catchup=False
) as dag:
create_table = PostgresOperator(
task_id='create_table',
postgres_conn_id='postgres_default',
sql=create_table_query
)
insert_data = PostgresOperator(
task_id='combine',
postgres_conn_id='postgres_default',
sql=combine_data_query
)
create_table >> insert_data
The second DAG creates and populates a reporting table (adoption_reporting_long) using data from the aggregated table (animal_adoptions_combined) created in your first DAG:
from airflow import DAG
from airflow.providers.postgres.operators.postgres import PostgresOperator
from datetime import datetime, timedelta
aggregate_reporting_query = '''
INSERT INTO adoption_reporting_long (date, type, number)
SELECT c.date, c.type, COUNT(c.type)
FROM animal_adoptions_combined c
GROUP BY date, type;
'''
with DAG('lineage-reporting-postgres',
start_date=datetime(2020, 6, 1),
max_active_runs=1,
schedule_interval='@daily',
default_args={
'retries': 1,
'retry_delay': timedelta(minutes=1)
},
catchup=False
) as dag:
create_table = PostgresOperator(
task_id='create_reporting_table',
postgres_conn_id='postgres_default',
sql='CREATE TABLE IF NOT EXISTS adoption_reporting_long (date DATE, type VARCHAR, number INTEGER);',
)
insert_data = PostgresOperator(
task_id='reporting',
postgres_conn_id='postgres_default',
sql=aggregate_reporting_query
)
create_table >> insert_data
If you run these DAGs in Airflow, and then go to Marquez, you will see a list of your jobs, including the four tasks from the previous DAGs.

Then, if you click one of the jobs from your DAGs, you see the full lineage graph.
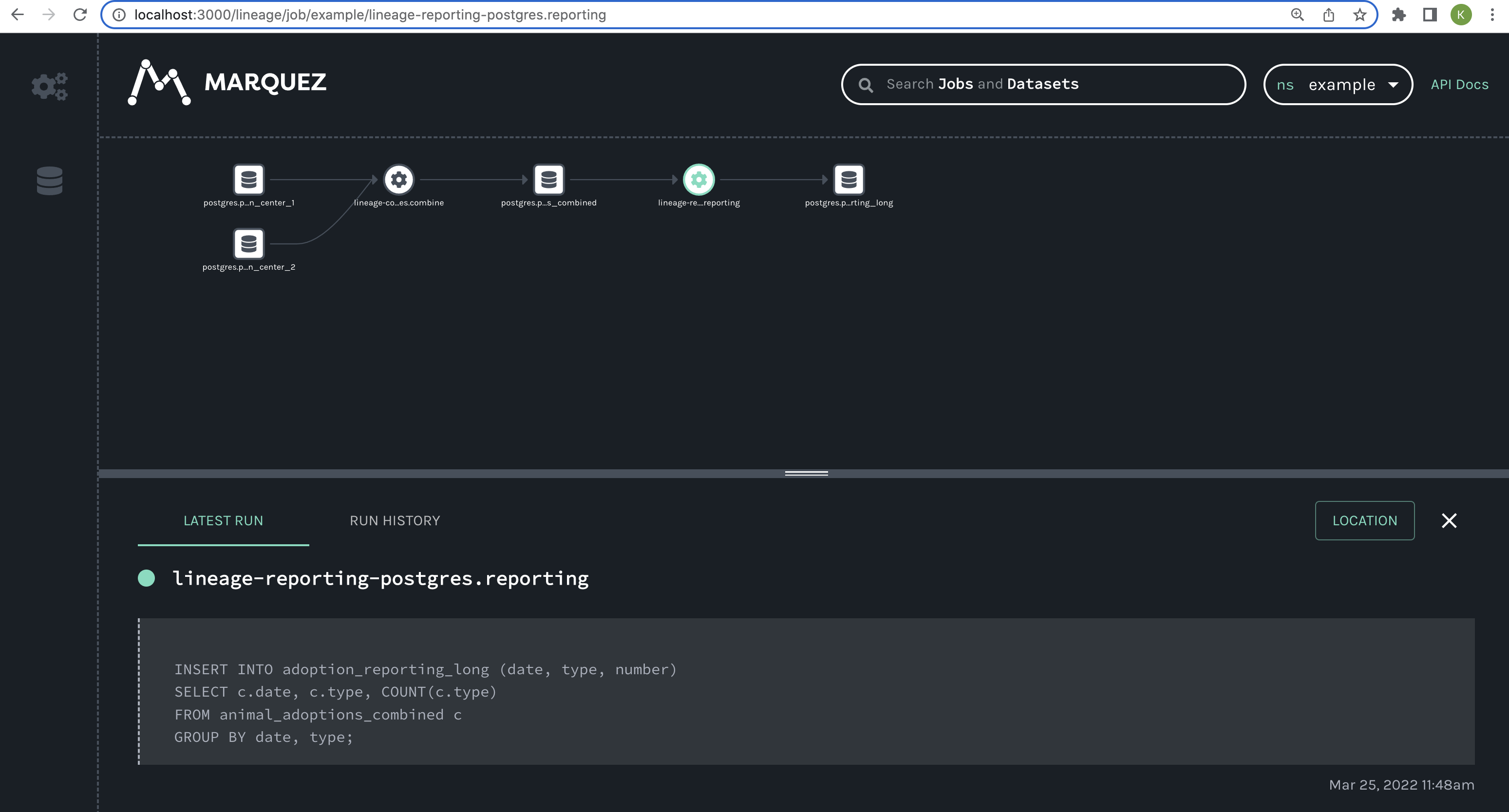
The lineage graph shows:
- Two origin datasets that are used to populate the combined data table;
- The two jobs (tasks) from your DAGs that result in new datasets:
combineandreporting; - Two new datasets that are created by those jobs.
The lineage graph shows you how these two DAGs are connected and how data flows through the entire pipeline, giving you insight you wouldn't have if you were to view these DAGs in the Airflow UI alone.
Lineage on Astro
For Astronomer customers using Astro, OpenLineage integration is built in. The Lineage tab in the Astronomer UI provides multiple pages that can help you troubleshoot issues with your data pipelines and understand the movement of data across your Organization. For more on lineage capabilities with Astro, see View lineage on Astro or contact us.
Limitations
OpenLineage is rapidly evolving, and new functionality and integrations are being added all the time. At the time of writing, the following are limitations when using OpenLineage with Airflow:
The OpenLineage integration with Airflow 2 is currently experimental.
You must be running Airflow 2.3.0+ with OpenLineage 0.8.1+ to get lineage data for failed task runs.
Only the following operators have bundled extractors (needed to collect lineage data out of the box):
PostgresOperatorSnowflakeOperatorBigQueryOperatorMySqlOperatorGreatExpectationsOperatorTo get lineage data from other operators, you can create your own custom extractor.
To get lineage data from an external system connected to Airflow, such as Apache Spark, you'll need to configure an OpenLineage integration with that system in addition to Airflow.