Datasets and data-aware scheduling in Airflow
Datasets and data-aware scheduling were made available in Airflow 2.4. DAGs that access the same data now have explicit, visible relationships, and DAGs can be scheduled based on updates to these datasets. This feature helps make Airflow data-aware and expands Airflow scheduling capabilities beyond time-based methods such as cron.
Datasets can help resolve common issues. For example, consider a data engineering team with a DAG that creates a dataset and an analytics team with a DAG that analyses the dataset. Using datasets, the data analytics DAG runs only when the data engineering team's DAG publishes the dataset.
In this guide, you'll learn about datasets in Airflow and how to use them to implement triggering of DAGs based on dataset updates. You'll also learn how datasets work with the Astro Python SDK.
Assumed knowledge
To get the most out of this guide, you should have an existing knowledge of:
- Airflow scheduling concepts. See Scheduling and Timetables in Airflow.
- Creating dependencies between DAGs. See Cross-DAG Dependencies.
- The Astro Python SDK. See Using the Astro Python SDK.
Dataset concepts
You can define datasets in your Airflow environment and use them to create dependencies between DAGs. To define a dataset, instantiate the Dataset class and provide a string to identify the location of the dataset. This string must be in the form of a valid Uniform Resource Identifier (URI).
In Airflow 2.4, the URI is not used to connect to an external system and there is no awareness of the content or location of the dataset. However, using this naming convention helps you to easily identify the datasets that your DAG accesses and ensures compatibility with future Airflow features.
The dataset URI is saved as plain text, so it is recommended that you hide sensitive values using environment variables or a secrets backend.
You can reference the dataset in a task by passing it to the task's outlets parameter. outlets is part of the BaseOperator, so it's available to every Airflow operator.
When you define a task's outlets parameter, Airflow labels the task as a producer task that updates the datasets. It is up to you to determine which tasks should be considered producer tasks for a dataset. As long as a task has an outlet dataset, Airflow considers it a producer task even if that task doesn't operate on the referenced dataset. In the following example, Airflow treats both upstream_task_1 and upstream_task_2 as producer tasks even though they only run sleep in a bash shell.
from airflow import DAG, Dataset
# Define datasets
dag1_dataset = Dataset('s3://dataset1/output_1.txt')
dag2_dataset = Dataset('s3://dataset2/output_2.txt')
with DAG(
dag_id='dataset_upstream1',
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
schedule='@daily',
) as dag1:
BashOperator(
task_id='upstream_task_1',
bash_command="sleep 5",
outlets=[dag1_dataset] # Define which dataset is updated by this task
)
BashOperator(
task_id='upstream_task_2',
bash_command="sleep 5",
outlets=[dag2_dataset] # Define which dataset is updated by this task
)
After a dataset is defined in one or more producer tasks, consumer DAGs in your Airflow environment listen to the producer tasks and run whenever the task completes, rather than running on a time-based schedule. For example, if you have a DAG that should run when dag1_dataset and dag2_dataset are updated, you define the DAG's schedule using the names of the datasets.
Any task that is scheduled with a dataset is considered a consumer task even if that task doesn't consume the referenced dataset. In other words, it is up to you as the DAG author to correctly reference and use the dataset that the consumer DAG is scheduled on.
dag1_dataset = Dataset('s3://dataset1/output_1.txt')
dag2_dataset = Dataset('s3://dataset2/output_2.txt')
with DAG(
dag_id='dataset_downstream_1_2',
catchup=False,
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
schedule=[dag1_dataset, dag2_dataset],
tags=['downstream'],
) as dag3:
BashOperator(
task_id='downstream_2',
bash_command="sleep 5"
)
Any number of datasets can be provided to the schedule parameter as a list. The DAG is triggered after all tasks that update those datasets have completed.
When you work with datasets, keep the following considerations in mind:
- Datasets can only be used by DAGs in the same Airflow environment.
- Airflow monitors datasets only within the context of DAGs and tasks. It does not monitor updates to datasets that occur outside of Airflow.
- Consumer DAGs that are scheduled on a dataset are triggered every time a task that updates that dataset completes successfully. For example, if
task1andtask2both producedataset_a, a consumer DAG ofdataset_aruns twice - first whentask1completes, and again whentask2completes. - Consumer DAGs scheduled on a dataset are triggered as soon as the first task with that dataset as an outlet finishes, even if there are downstream producer tasks that also operate on the dataset.
- Scheduling a DAG on a dataset update cannot currently be combined with any other type of schedule. For example, you can't schedule a DAG on an update to a dataset and a timetable.
For more information about datasets, see Data-aware scheduling.
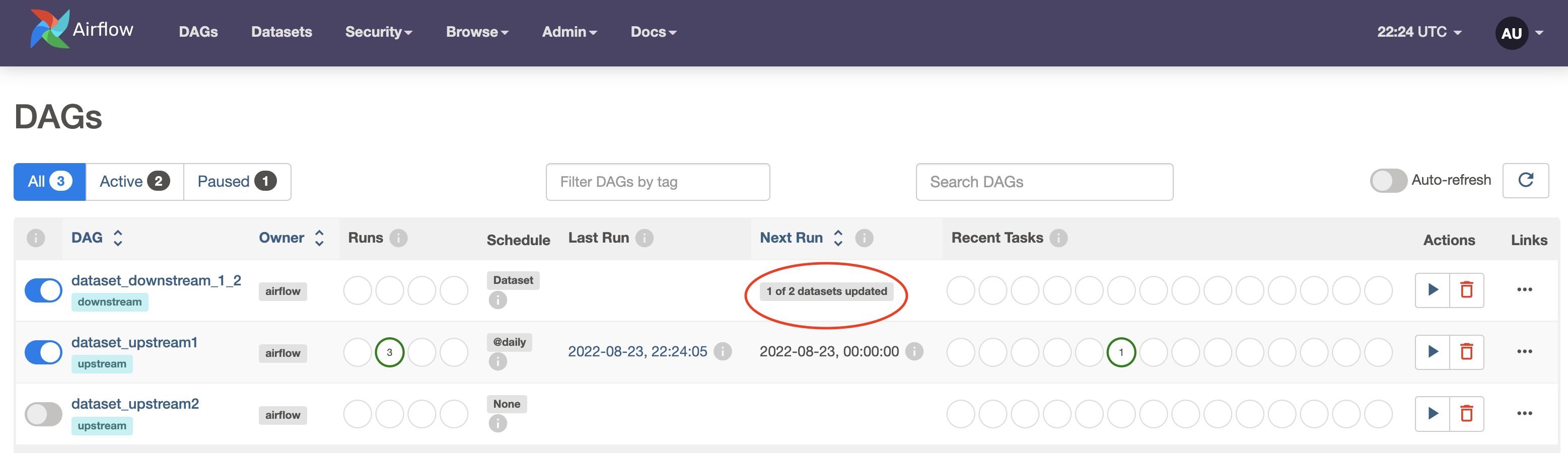
The Datasets tab, and the DAG Dependencies view in the Airflow UI give you observability for datasets and data dependencies in the DAG's schedule.
On the DAGs view, you can see that your dataset_downstream_1_2 DAG is scheduled on two producer datasets (one in dataset_upstream1 and dataset_upstream2), and its next run is pending one dataset update. At this point the dataset_upstream DAG has run and updated its dataset, but the dataset_upstream2 DAG has not.
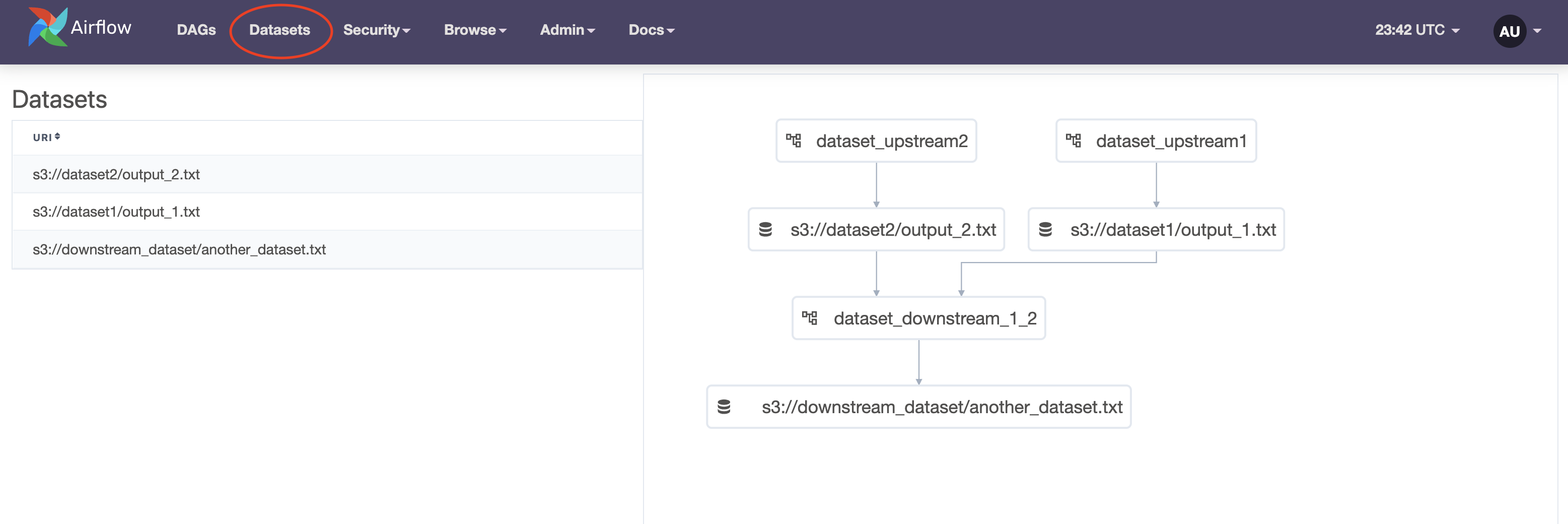
The new Datasets tab shows a list of all datasets in your Airflow environment and a graph showing how your DAGs and datasets are connected.
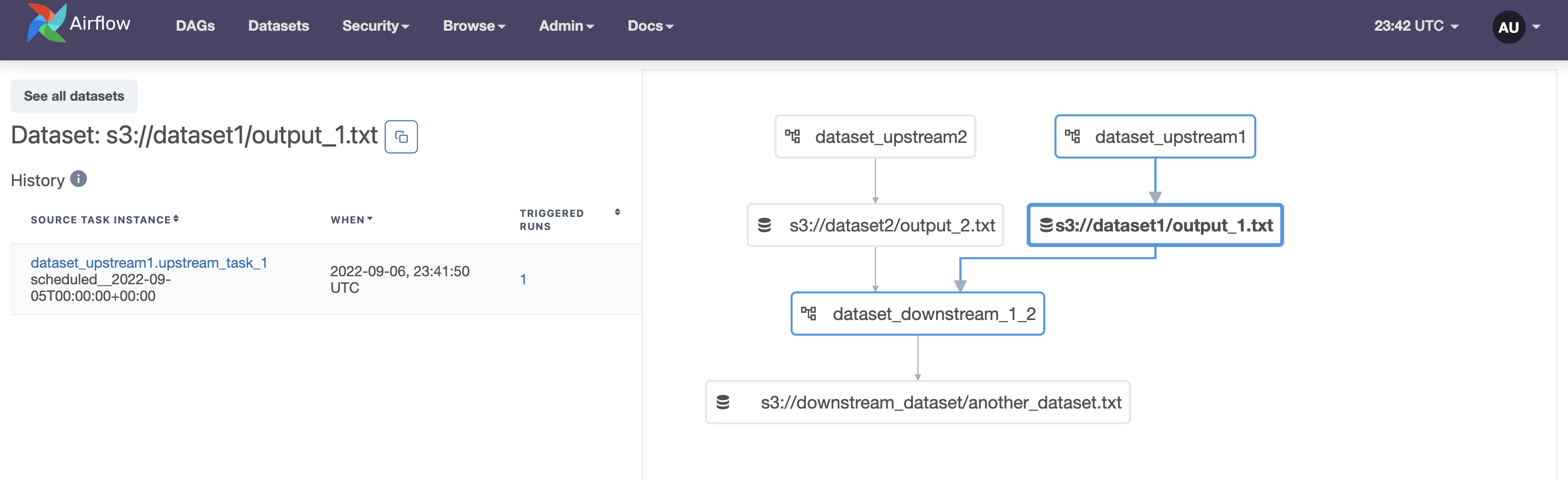
Click one of the datasets to display a list of task instances that updated the dataset and a highlighted view of that dataset and its connections on the graph.
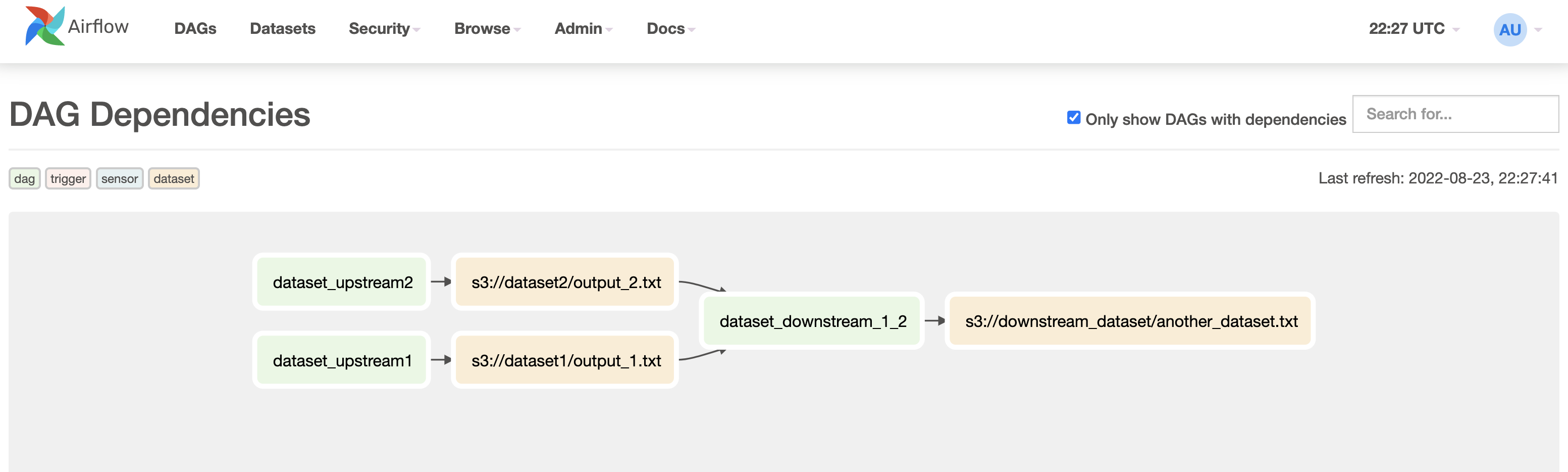
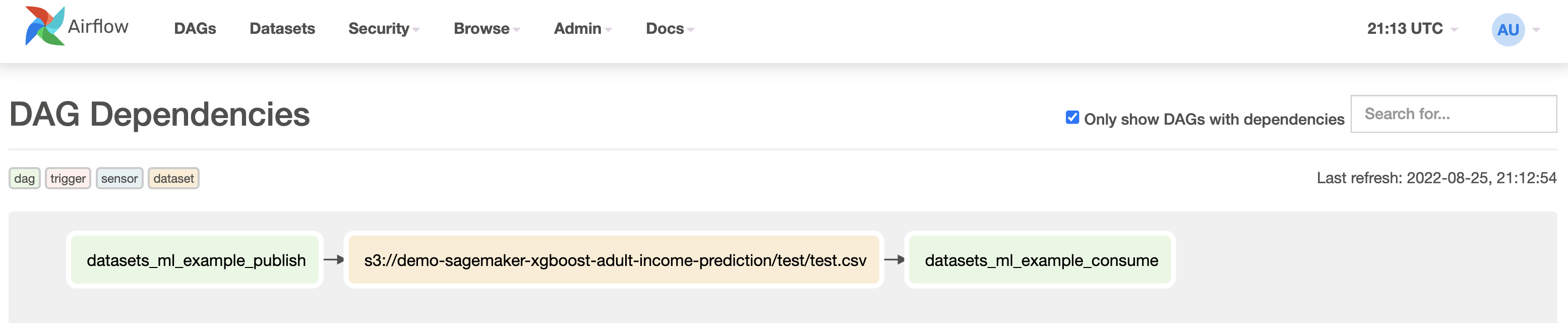
The DAG Dependencies view (found under the Browse tab) shows a graph of all dependencies between DAGs (in green) and datasets (in orange) in your Airflow environment.
Example implementation
In this section you'll learn how datasets and data-aware scheduling can help with a classic ML Ops use case. In this example, it's assumed that two teams are responsible for DAGs that provide data, train a model, and publish the results.
In this example, a data engineering team has a DAG that sends data to an Amazon S3 bucket and a data science team has another DAG that uses the data to train a Sagemaker model and publish the results to Redshift.
Using datasets, the data science team can schedule their DAG to run only when the data engineering team's DAG has completed sending the data to the Amazon S3 bucket, ensuring that only the most recent data is used in the model.
The following is an example of the data engineering team's DAG:
from airflow import Dataset
from airflow.decorators import task, dag
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
import pendulum
s3_bucket = 'sagemaker-us-east-2-559345414282'
test_s3_key = 'demo-sagemaker-xgboost-adult-income-prediction/test/test.csv'
dataset_uri = 's3://' + test_s3_key
@dag(
schedule='@daily',
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
)
def datasets_ml_example_publish():
@task(outlets=Dataset(dataset_uri))
def upload_data_to_s3(s3_bucket, test_s3_key):
"""
Uploads validation data to S3 from /include/data
"""
s3_hook = S3Hook(aws_conn_id='aws-sagemaker')
# Upload the file using the .load_file() method
s3_hook.load_file(
filename='include/data/test.csv',
key=test_s3_key,
bucket_name=s3_bucket,
replace=True
)
upload_data = upload_data_to_s3(s3_bucket, test_s3_key)
datasets_ml_example_publish = datasets_ml_example_publish()
This DAG has a single task, upload_data_to_s3, that publishes the data. An outlet dataset is defined in the @task decorator using outlets=Dataset(dataset_uri) where the dataset URI is defined at the top of the DAG script.
The data science team can then provide that same dataset URI to the schedule parameter in their DAG:
from airflow import DAG, Dataset
from airflow.providers.amazon.aws.operators.sagemaker_transform import (
SageMakerTransformOperator
)
from airflow.providers.amazon.aws.transfers.s3_to_redshift import (
S3ToRedshiftOperator
)
from datetime import datetime, timedelta
# Define variables used in config and Python function
date = '{{ ds_nodash }}' # Date for transform job name
s3_bucket = 'sagemaker-us-east-2-559345414282' # S3 Bucket used with SageMaker instance
test_s3_key = 'demo-sagemaker-xgboost-adult-income-prediction/test/test.csv' # Test data S3 key
output_s3_key = 'demo-sagemaker-xgboost-adult-income-prediction/output/' # Model output data S3 key
sagemaker_model_name = "sagemaker-xgboost-2021-08-03-23-25-30-873" # SageMaker model name
dataset_uri = 's3://' + test_s3_key
# Define transform config for the SageMakerTransformOperator
transform_config = {
"TransformJobName": "test-sagemaker-job-{0}".format(date),
"TransformInput": {
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": "s3://{0}/{1}".format(s3_bucket, test_s3_key)
}
},
"SplitType": "Line",
"ContentType": "text/csv",
},
"TransformOutput": {
"S3OutputPath": "s3://{0}/{1}".format(s3_bucket, output_s3_key)
},
"TransformResources": {
"InstanceCount": 1,
"InstanceType": "ml.m5.large"
},
"ModelName": sagemaker_model_name
}
with DAG(
'datasets_ml_example_consume',
start_date=datetime(2021, 7, 31),
max_active_runs=1,
schedule=[Dataset(dataset_uri)], # Schedule based on the dataset published in another DAG
default_args={
'retries': 1,
'retry_delay': timedelta(minutes=1),
'aws_conn_id': 'aws-sagemaker'
},
catchup=False
) as dag:
predict = SageMakerTransformOperator(
task_id='predict',
config=transform_config
)
results_to_redshift = S3ToRedshiftOperator(
task_id='save_results',
s3_bucket=s3_bucket,
s3_key=output_s3_key,
schema="PUBLIC",
table="results",
copy_options=['csv'],
)
predict >> results_to_redshift
The dependency between the two DAGs is straightforward to implement and can be viewed alongside the dataset in the Airflow UI.
Datasets with the Astro Python SDK
If you are using the Astro Python SDK version 1.1 or later, you do not need to make any code updates to use datasets. Datasets are automatically registered for any functions with output tables and you do not need to define any outlet parameters.
The following example DAG results in three registered datasets: one for each load_file function and one for the resulting data from the transform function.
import os
from datetime import datetime
import pandas as pd
from airflow.decorators import dag
from astro.files import File
from astro.sql import (
load_file,
transform,
)
from astro.sql.table import Table
SNOWFLAKE_CONN_ID = "snowflake_conn"
AWS_CONN_ID = "aws_conn"
# The first transformation combines data from the two source tables
@transform
def extract_data(homes1: Table, homes2: Table):
return """
SELECT *
FROM {{homes1}}
UNION
SELECT *
FROM {{homes2}}
"""
@dag(start_date=datetime(2021, 12, 1), schedule_interval="@daily", catchup=False)
def example_sdk_datasets():
# Initial load of homes data csv's from S3 into Snowflake
homes_data1 = load_file(
task_id="load_homes1",
input_file=File(path="s3://airflow-kenten/homes1.csv", conn_id=AWS_CONN_ID),
output_table=Table(name="HOMES1", conn_id=SNOWFLAKE_CONN_ID),
if_exists='replace'
)
homes_data2 = load_file(
task_id="load_homes2",
input_file=File(path="s3://airflow-kenten/homes2.csv", conn_id=AWS_CONN_ID),
output_table=Table(name="HOMES2", conn_id=SNOWFLAKE_CONN_ID),
if_exists='replace'
)
# Define task dependencies
extracted_data = extract_data(
homes1=homes_data1,
homes2=homes_data2,
output_table=Table(name="combined_homes_data"),
)
example_sdk_datasets = example_sdk_datasets()
