Dynamically generating DAGs in Airflow
In Airflow, DAGs are defined as Python code. Airflow executes all Python code in the dags_folder and loads any DAG objects that appear in globals(). The simplest way to create a DAG is to write it as a static Python file.
Sometimes, manually writing DAGs isn't practical. Maybe you have hundreds or thousands of DAGs that do similar things with just a parameter changing between them. Or maybe you need a set of DAGs to load tables, but don't want to manually update DAGs every time the tables change. In these cases, and others, it makes more sense to dynamically generate DAGs.
Because everything in Airflow is code, you can dynamically generate DAGs using Python alone. As long as a DAG object in globals() is created by Python code that is stored in the dags_folder, Airflow will load it. In this guide, you'll learn how to dynamically generate DAGs. You'll learn when DAG generation is the preferred option and what pitfalls to avoid.
All code used in this tutorial is located in the Astronomer Registry.
Assumed knowledge
To get the most out of this guide, you should have an understanding of:
- Airflow DAGs. See Introduction to Airflow DAGs.
Single-file methods
One method for dynamically generating DAGs is to have a single Python file which generates DAGs based on some input parameter(s). For example, a list of APIs or tables. A common use case for this is an ETL or ELT-type pipeline where there are many data sources or destinations. This requires creating many DAGs that all follow a similar pattern.
Some benefits of the single-file method:
- It's straightforward to implement.
- It can accommodate input parameters from many different sources.
- Adding DAGs is nearly instantaneous since it requires only changing the input parameters.
The single-file method has the following disadvantages:
- Your visibility into the code behind any specific is limited because a DAG file isn't created.
- Generation code is executed every time the DAG is parsed because this method requires a Python file in the
dags_folder. How frequently this occurs is controlled by themin_file_process_intervalparameter. This can cause performance issues if the total number of DAGs is large, or if the code is connecting to an external system such as a database.
In the following examples, the single-file method is implemented differently based on which input parameters are used for generating DAGs.
Example: Use a create_dag function
To dynamically create DAGs from a file, you need to define a Python function that will generate the DAGs based on an input parameter. In this case, you're going to define a DAG template within a create_dag function. The code here is very similar to what you would use when creating a single DAG, but it is wrapped in a method that allows for custom parameters to be passed in.
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
def create_dag(dag_id,
schedule,
dag_number,
default_args):
def hello_world_py(*args):
print('Hello World')
print('This is DAG: {}'.format(str(dag_number)))
dag = DAG(dag_id,
schedule_interval=schedule,
default_args=default_args)
with dag:
t1 = PythonOperator(
task_id='hello_world',
python_callable=hello_world_py,
dag_number=dag_number)
return dag
In this example, the input parameters can come from any source that the Python script can access. You can then set a simple loop (range(1, 4)) to generate these unique parameters and pass them to the global scope, thereby registering them as valid DAGs with the Airflow scheduler:
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
def create_dag(dag_id,
schedule,
dag_number,
default_args):
def hello_world_py(*args):
print('Hello World')
print('This is DAG: {}'.format(str(dag_number)))
dag = DAG(dag_id,
schedule_interval=schedule,
default_args=default_args)
with dag:
t1 = PythonOperator(
task_id='hello_world',
python_callable=hello_world_py)
return dag
# build a dag for each number in range(10)
for n in range(1, 4):
dag_id = 'loop_hello_world_{}'.format(str(n))
default_args = {'owner': 'airflow',
'start_date': datetime(2021, 1, 1)
}
schedule = '@daily'
dag_number = n
globals()[dag_id] = create_dag(dag_id,
schedule,
dag_number,
default_args)
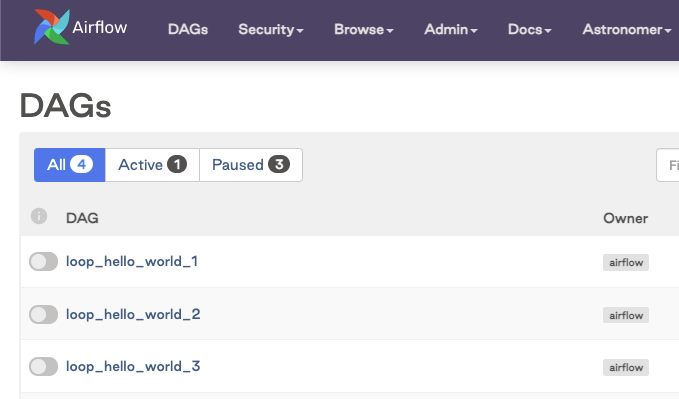
The DAGs appear in the Airflow UI:
Example: Generate DAGs from variables
As mentioned previously, the input parameters don't have to exist in the DAG file. Another common form of generating DAGs is by setting values in a Variable object.
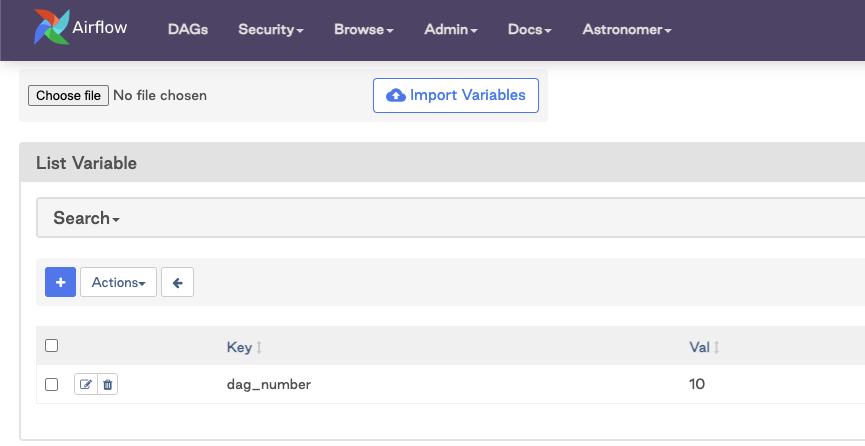
You can retrieve this value by importing the Variable class and passing it into your range. The default_var is set to 3 because you want the interpreter to register this file as valid regardless of whether the variable exists.
from airflow import DAG
from airflow.models import Variable
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
def create_dag(dag_id,
schedule,
dag_number,
default_args):
def hello_world_py(*args):
print('Hello World')
print('This is DAG: {}'.format(str(dag_number)))
dag = DAG(dag_id,
schedule_interval=schedule,
default_args=default_args)
with dag:
t1 = PythonOperator(
task_id='hello_world',
python_callable=hello_world_py)
return dag
number_of_dags = Variable.get('dag_number', default_var=3)
number_of_dags = int(number_of_dags)
for n in range(1, number_of_dags):
dag_id = 'hello_world_{}'.format(str(n))
default_args = {'owner': 'airflow',
'start_date': datetime(2021, 1, 1)
}
schedule = '@daily'
dag_number = n
globals()[dag_id] = create_dag(dag_id,
schedule,
dag_number,
default_args)
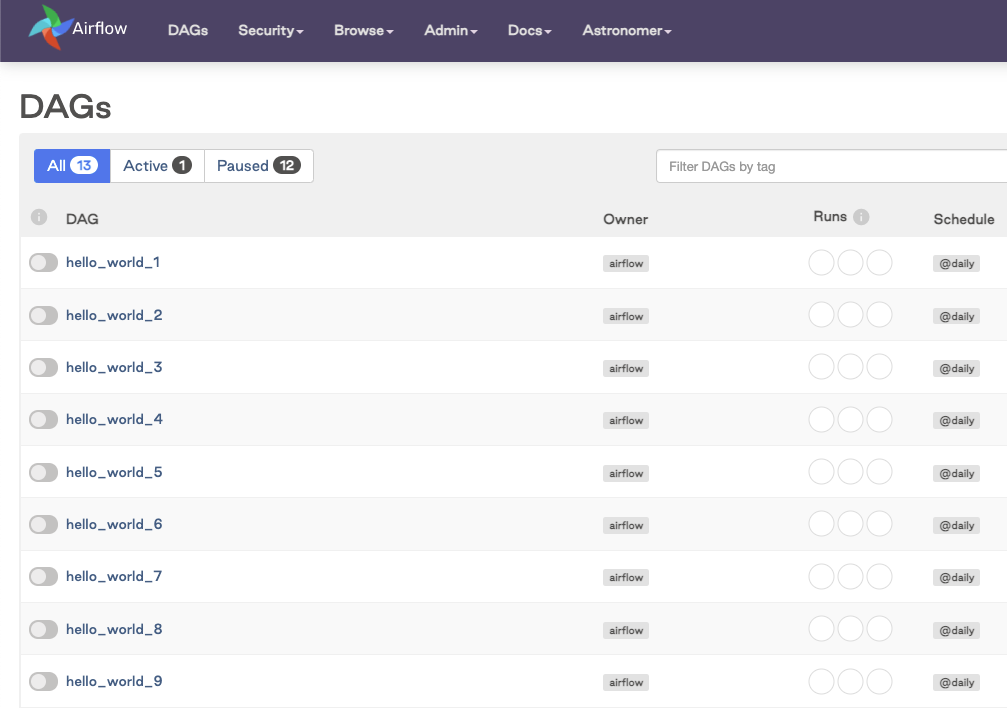
The DAGs appear in the Airflow UI:
Example: Generate DAGs from connections
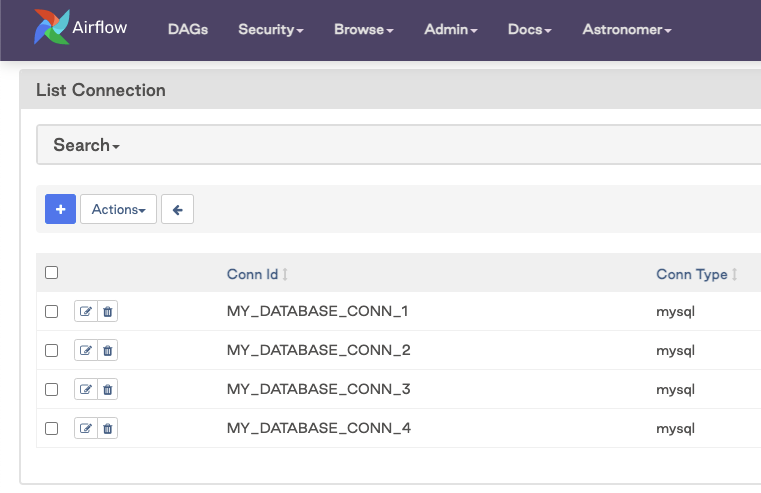
Another way to define input parameters for dynamically generated DAGs is to define Airflow connections. This can be a good option if each of your DAGs connects to a database or an API. Because you'll be setting up the connections anyway, creating the DAGs from that source avoids redundant work.
To implement this method, you pull the connections from your Airflow metadata database by instantiating the session and querying the connection table. You can also filter this query so that it only pulls connections that match a specific criteria.
from airflow import DAG, settings
from airflow.models import Connection
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
def create_dag(dag_id,
schedule,
dag_number,
default_args):
def hello_world_py(*args):
print('Hello World')
print('This is DAG: {}'.format(str(dag_number)))
dag = DAG(dag_id,
schedule_interval=schedule,
default_args=default_args)
with dag:
t1 = PythonOperator(
task_id='hello_world',
python_callable=hello_world_py)
return dag
session = settings.Session()
conns = (session.query(Connection.conn_id)
.filter(Connection.conn_id.ilike('%MY_DATABASE_CONN%'))
.all())
for conn in conns:
dag_id = 'connection_hello_world_{}'.format(conn[0])
default_args = {'owner': 'airflow',
'start_date': datetime(2018, 1, 1)
}
schedule = '@daily'
dag_number = conn
globals()[dag_id] = create_dag(dag_id,
schedule,
dag_number,
default_args)
You are accessing the Models library to bring in the Connection class (as you did previously with the Variable class). You are also accessing the Session() class from settings, which will allow us to query the current database session.
All of the connections that match our filter have now been created as a unique DAG.
Multiple-file methods
Another method for dynamically generating DAGs is to use code to generate full Python files for each DAG. The end result of this method is having one Python file per generated DAG in your dags_folder.
One way of implementing this method in production is to have a Python script that generates DAG files when executed as part of a CI/CD workflow. The DAGs are generated during the CI/CD build and then deployed to Airflow. You could also have another DAG that runs the generation script periodically.
Some benefits of this method:
- It's more scalable than single-file methods. Because the DAG files aren't being generated by parsing code in the
dags_folder, the DAG generation code isn't executed on every scheduler heartbeat. - Since DAG files are being explicitly created before deploying to Airflow, you have full visibility into the DAG code, including from the Code button in the Airflow UI.
Some disadvantages of this method:
- It can be complex to set up.
- Changes to DAGs or additional DAGs won't be generated until the script is run, which in some cases requires a deployment.
Example: Generate DAGs from JSON config files
One way of implementing a multiple-file method is using a Python script to generate DAG files based on a set of JSON configuration files. For this example, you'll assume that all DAGs have a single task that uses the PostgresOperator to execute a query. This use case might be relevant for a team of analysts who need to schedule SQL queries, where the DAG is largely the same, but the query and the schedule change.
To start, you'll create a DAG 'template' file that defines the DAG's structure. This looks just like a regular DAG file, but specific variables have been added to define where the information is going to be dynamically generated, namely dag_id, scheduletoreplace, and querytoreplace.
from airflow import DAG
from airflow.providers.postgres.operators.postgres import PostgresOperator
from datetime import datetime
default_args = {'owner': 'airflow',
'start_date': datetime(2021, 1, 1)
}
with DAG(dag_id,
schedule_interval=scheduletoreplace,
default_args=default_args,
catchup=False) as dag:
t1 = PostgresOperator(
task_id='postgres_query',
postgres_conn_id=connection_id,
sql=querytoreplace)
Next, you create a dag-config folder that will contain a JSON config file for each DAG. The config file should define the parameters discussed previously, the DAG ID, schedule interval, and query to be executed.
{
"DagId": "dag_file_1",
"Schedule": "'@daily'",
"Query":"'SELECT * FROM table1;'"
}
Finally, you create a Python script that will create the DAG files based on the template and the config files. The script loops through every config file in the dag-config/ folder, makes a copy of the template in the dags/ folder, and then overwrites the parameters in that file with the ones from the config file.
import json
import os
import shutil
import fileinput
config_filepath = 'include/dag-config/'
dag_template_filename = 'include/dag-template.py'
for filename in os.listdir(config_filepath):
with open(config_filepath + filename) as f:
config = json.load(f)
new_filename = 'dags/' + config['DagId'] + '.py'
shutil.copyfile(dag_template_filename, new_filename)
with fileinput.input(new_filename, inplace=True) as file:
for line in file:
new_line = line.replace('dag_id', "'" + config['DagId'] + "'")\
.replace('scheduletoreplace', config['Schedule'])\
.replace('querytoreplace', config['Query'])
print(new_line, end='')
To generate your DAG files, you can either run this script on demand or as part of your CI/CD workflow. After running the script, your final directory will appear similar to the example below, where the include/ directory contains the files from the previous example, and the dags/ directory contains the two dynamically generated DAGs:
dags/
├── dag_file_1.py
├── dag_file_2.py
include/
├── dag-template.py
├── generate-dag-files.py
└── dag-config
├── dag1-config.json
└── dag2-config.json
This is a straightforward example that works only if all of the DAGs follow the same pattern. However, it could be expanded upon to have dynamic inputs for tasks, dependencies, different operators, and so on.
DAG factory
A notable tool for dynamically creating DAGs from the community is dag-factory. dag-factory is an open source Python library for dynamically generating Airflow DAGs from YAML files.
To use dag-factory, you can install the package in your Airflow environment and create YAML configuration files for generating your DAGs. You can then build the DAGs by calling the dag-factory.generate_dags() method in a Python script. The following example was taken from the dag-factory README:
from airflow import DAG
import dagfactory
dag_factory = dagfactory.DagFactory("/path/to/dags/config_file.yml")
dag_factory.clean_dags(globals())
dag_factory.generate_dags(globals())
Scalability
Dynamically generating DAGs can cause performance issues when used at scale. Whether or not any particular method will cause problems is dependent on your total number of DAGs, your Airflow configuration, and your infrastructure. Keep the following considerations in mind when considering dynamically generating DAGs:
- Any code in the
dags_folderis executed either everymin_file_processing_intervalor as fast as the DAG file processor can, whichever is less frequent. Methods where the code is dynamically generating DAGs, such as the single-file method, are more likely to cause performance issues at scale. - If you are reaching out to a database to create your DAGs, you will be querying frequently. Be conscious of your database's ability to handle such frequent connections and any costs you may incur for each request from your data provider.
- To help with potential performance issues, you can increase the
min_file_processing_intervalto a higher value. Consider this option if you know that your DAGs are not changing frequently and if you can tolerate some delay in the dynamic DAGs changing in response to the external source that generates them.
Upgrading to Airflow 2.0 to make use of the HA Scheduler should help resolve potential performance issues. Additional optimization might be required. There is no single right way to implement or scale dynamically generated DAGs, but the flexibility of Airflow means there are many ways to arrive at a solution that works for your organization.