An introduction to Apache Airflow
Apache Airflow is an open source tool for programmatically authoring, scheduling, and monitoring data pipelines. It has over 9 million downloads per month and an active OSS community. Airflow allows data practitioners to define their data pipelines as Python code in a highly extensible and infinitely scalable way.
This guide offers an introduction to Apache Airflow and its core concepts. You'll learn:
- The history of Apache Airflow.
- Why you should use Airflow.
- When you should use Airflow.
- Core Airflow concepts.
For a hands-on introduction to Airflow using the Astro CLI, see Get started with Apache Airflow.
Assumed knowledge
To get the most out of this guide, you should have an understanding of:
- Basic Python. See the Python Documentation.
History
Airflow started as an open source project at Airbnb. In 2015, Airbnb was growing rapidly and struggling to manage the vast quantities of internal data it generated every day. Airbnb data engineers, data scientists, and analysts had to regularly write scheduled batch jobs to automate processes. To satisfy the need for a robust scheduling tool, Maxime Beauchemin created Airflow to allow Airbnb to quickly author, iterate, and monitor batch data pipelines.
Airflow has come a long way since Maxime's first commit. The project joined the official Apache Foundation Incubator in April of 2016, and graduated as a top-level project in January 2019. As of August 2022 Airflow has over 2,000 contributors, 16,900 commits and 26,900 stars on GitHub.
On December 17th 2020, Airflow 2.0 was released, bringing with it major upgrades and powerful new features. Airflow is used by thousands of data engineering teams around the world and adoption continues to accelerate as the community grows stronger.
Why use Airflow
Apache Airflow is a platform for programmatically authoring, scheduling, and monitoring workflows. It is especially useful for creating and orchestrating complex data pipelines.
Data orchestration sits at the heart of any modern data stack and provides elaborate automation of data pipelines. With orchestration, actions in your data pipeline become aware of each other and your data team has a central location to monitor, edit, and troubleshoot their workflows.
Airflow provides many benefits, including:
- Dynamic data pipelines: In Airflow, pipelines are defined as Python code. Anything you can do in Python, you can do in Airflow.
- CI/CD for data pipelines: With all the logic of your workflows defined in Python, it is possible to implement CI/CD processes for your data pipelines.
- Tool agnosticism: Airflow can connect to any application in your data ecosystem that allows connections through an API.
- High extensibility: For many commonly used data engineering tools, integrations exist in the form of provider packages, which are routinely extended and updated.
- Infinite scalability: Given enough computing power, you can orchestrate as many processes as you need, no matter the complexity of your pipelines.
- Visualization: The Airflow UI provides an immediate overview of your data pipelines.
- Stable REST API: The Airflow REST API allows Airflow to interact with RESTful web services.
- Ease of use: With the Astro CLI, you can run a local Airflow environment with only three bash commands.
- Active and engaged OSS community: With millions of users and thousands of contributors, Airflow is here to stay and grow.
When to use Airflow
Airflow can be used for almost any batch data pipeline, and there are a significant number of documented use cases in the community. Because of its extensibility, Airflow is particularly powerful for orchestrating jobs with complex dependencies in multiple external systems.
The following diagram illustrates a complex use case that can be accomplished with Airflow. By writing pipelines in code and using Airflow providers, you can integrate with any number of different systems with just a single platform for orchestration and monitoring.
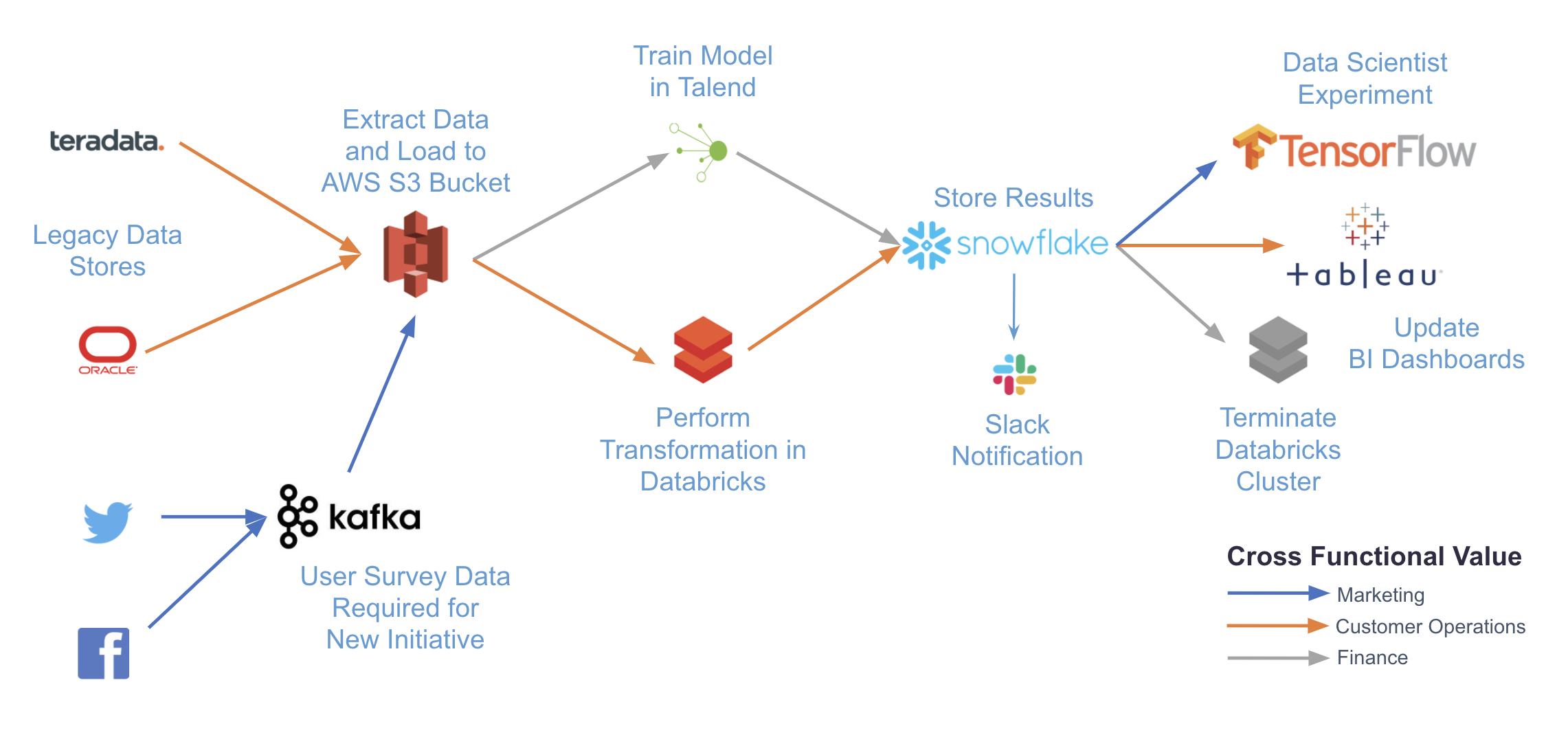
Some common use cases of Airflow include:
- ETL/ELT pipelines: For example, running a write, audit, publish pattern on data in Snowflake as shown in Orchestrating Snowflake Queries with Airflow.
- MLOps: For example, using Airflow with Tensorflow and MLFlow as shown in Using Airflow with Tensorflow and MLFlow.
- Operationalized analytics: For example, orchestrating a pipeline to extract insights from your data and display them in dashboards as shown in Using Airflow as a Data Analyst.
Core Airflow concepts
To navigate Airflow resources, it is helpful to have a general understanding of the following core Airflow concepts:
- DAG: Directed Acyclic Graph. An Airflow DAG is a workflow defined as a graph, where all dependencies between nodes are directed and nodes do not self-reference. For more information on Airflow DAGs, see Introduction to Airflow DAGs.
- DAG run: The execution of a DAG at a specific point in time. A DAG run can be scheduled or manually triggered.
- Task: A step in a DAG describing a single unit of work.
- Task instance: The execution of a task at a specific point in time.
When authoring DAGs, you use operators. An operator is an abstraction over Python code designed to perform a specific action and takes the form of a function that accepts parameters. Each operator in your DAG code corresponds to one Airflow task.
The following are the primary operator categories:
- Action operators: Execute a function. For example, the PythonOperator or the BashOperator.
- Transfer operators: Move data from a source to a destination. For example, the S3ToRedshiftOperator.
- Sensors: Wait for something to happen. For example, the ExternalTaskSensor or the HttpSensorAsync.
While operators are defined individually, they can pass information to each other by using XComs. To learn more about operators, see Operators 101.
Some commonly used action operators such as the PythonOperator are part of core Airflow and are automatically installed in your Airflow instance. Operators used to interact with external systems are maintained separately to Airflow in provider packages.
Providers are packages that are maintained by the community and include all of the core operators, hooks, and sensors for a given service, for example:
To view the available providers and operators, see the Astronomer Registry.
Airflow components
When working with Airflow, it is important to understand the underlying components of its infrastructure. Knowing which components are available and their purpose can help you develop your DAGs, troubleshoot issues, and run Airflow successfully.
The following Airflow components must be running at all times:
- Webserver: A Flask server running with Gunicorn that serves the Airflow UI.
- Scheduler: A Daemon responsible for scheduling jobs. This is a multi-threaded Python process that determines what tasks need to be run, when they need to be run, and where they are run.
- Database: A database where all DAG and task metadata are stored. This is typically a Postgres database, but MySQL, MsSQL, and SQLite are also supported.
- Executor: The mechanism that defines how the available computing resources are used to execute tasks. An executor is running within the scheduler whenever Airflow is up.
Additionally, you may also have the following situational components:
- Triggerer: A separate process which supports deferrable operators. This component is optional and must be run separately.
- Worker: The process that executes tasks, as defined by the executor. Depending on which executor you choose, you may or may not have workers as part of your Airflow infrastructure.
To learn more about the Airflow infrastructure, see Airflow Components.