Enable data lineage for external systems
To generate lineage graphs for your data pipelines, you first need to configure your data pipelines to emit lineage data. Because lineage data can be generated in all stages of your pipeline, you can configure pipeline components outside of Astro, such as dbt or Databricks, to emit lineage data whenever they're running a job. Coupled with lineage data emitted from your DAGs, Astro generates a lineage graph that can provide context to your data before, during, and after it reaches your Deployment.
Lineage architecture
Lineage data is generated by OpenLineage. OpenLineage is an open source standard for lineage data creation and collection. The OpenLineage API sends metadata about running jobs and datasets to Astro. Every Astro Organization includes an OpenLineage API key that you can use in your external systems to send lineage data back to your Control Plane.
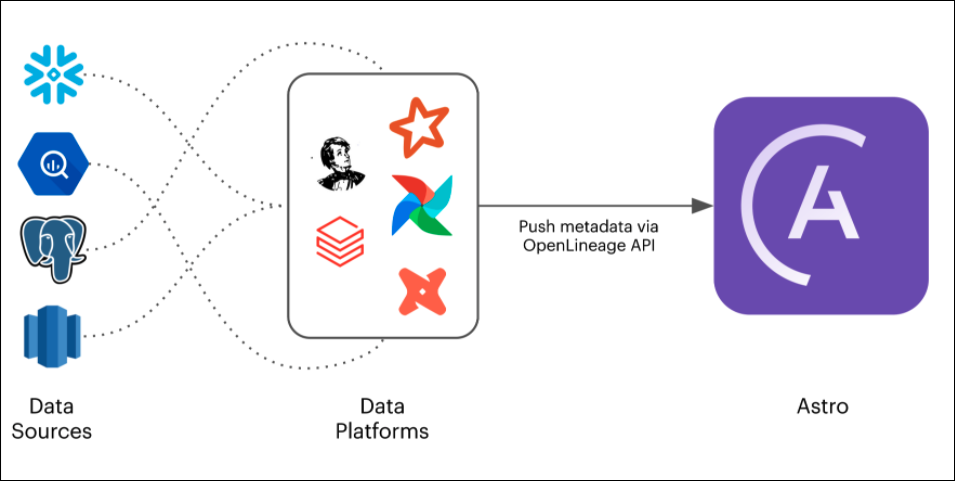
Configuring a system to send lineage data requires:
- Installing an OpenLineage backend to emit lineage data from the system.
- Specifying your Organization's OpenLineage API endpoint to send lineage data to the Astro control plane.
You can access this documentation directly from the Lineage tab in the Cloud UI. The embedded documentation additionally loads your Organization's configuration values, such as your OpenLineage API key and your Astro base domain, directly into configuration steps.
Retrieve your OpenLineage API key
To send lineage data from an external system to Astro, you must specify your Organization's OpenLineage API key in the external system's configuration.
In the Cloud UI, click the Lineage tab.
In the left menu, click Integrations:
In Getting Started, copy the value below OpenLineage API Key.
For more information about how to configure this API key in an external system, review the Integration Guide for the system.
Integration guides
- Astronomer
- Databricks
- Great Expectations
- Apache Spark
- dbt
Lineage is configured automatically for all Deployments on Astro Runtime 4.2.0+. To add lineage to an existing Deployment that is running on a version of Astro Runtime that is lower than 4.2.0, upgrade to the latest version. For instructions, see Upgrade Astro Runtime.
Note: If you don't see lineage features enabled for a Deployment on Runtime 4.2.0+, then you might need to push code to the Deployment to trigger the automatic configuration process.
To configure lineage on an existing Deployment on Runtime <4.2.0 without upgrading Runtime:
In your locally hosted Astro project, update your
requirements.txtfile to include the following line:openlineage-airflowPush your changes to your Deployment.
In the Cloud UI, set the following environment variables in your Deployment:
AIRFLOW__LINEAGE__BACKEND=openlineage.lineage_backend.OpenLineageBackend
OPENLINEAGE_NAMESPACE=<your-deployment-namespace>
OPENLINEAGE_URL=https://<your-astro-base-domain>
OPENLINEAGE_API_KEY=<your-lineage-api-key>
Verify
To view lineage metadata, go to the Organization view of the Cloud UI and open the Lineage tab. You should see your most recent DAG run represented as a data lineage graph in the Lineage page.
Note: Lineage information appears only for DAGs that use operators that have extractors defined in the
openlineage-airflowlibrary, such as thePostgresOperatorandSnowflakeOperator. For a list of supported operators, see Data lineage Support and Compatibility.
Note: If you don't see lineage data for a DAG even after configuring lineage in your Deployment, you might need to run the DAG at least once so that it starts emitting lineage data.
Use the information provided here to set up lineage collection for Spark running on a Databricks cluster.
Prerequisites
- A Databricks cluster.
Setup
In your Databricks File System (DBFS), create a new directory at
dbfs:/databricks/openlineage/.Download the latest OpenLineage
jarfile to the new directory. See Maven Central Repository.Download the
open-lineage-init-script.shfile to the new directory. See OpenLineage GitHub.In Databricks, run this command to create a cluster-scoped init script and install the
openlineage-sparklibrary at cluster initialization:dbfs:/databricks/openlineage/open-lineage-init-script.shIn the cluster configuration page for your Databricks cluster, specify the following Spark configuration:
bash
spark.driver.extraJavaOptions -Djava.security.properties=
spark.executor.extraJavaOptions -Djava.security.properties=
spark.openlineage.url https://<your-astro-base-domain>
spark.openlineage.apiKey <your-lineage-api-key>
spark.openlineage.namespace <NAMESPACE_NAME> // Astronomer recommends using a meaningful namespace like `spark-dev`or `spark-prod`.
Note: You override the JVM security properties for the spark driver and executor with an empty string as some TLS algorithms are disabled by default. For a more information, see this discussion.
After you save this configuration, lineage is enabled for all Spark jobs running on your cluster.
Verify Setup
To test that lineage was configured correctly on your Databricks cluster, run a test Spark job on Databricks. After your job runs, open the Lineage tab in the Cloud UI and go to the Explore page. If your configuration is successful, you'll see your Spark job appear in the Most Recent Runs table. Click a job run to see it within a lineage graph.
This guide outlines how to set up lineage collection for a dbt project.
Prerequisites
- A dbt project.
- The dbt CLI v0.20+.
- Your Astro base domain.
- Your Organization's OpenLineage API key.
Setup
On your local machine, run the following command to install the
openlineage-dbtlibrary:$ pip install openlineage-dbtConfigure the following environment variables in your shell:
OPENLINEAGE_URL=https://<your-astro-base-domain>
OPENLINEAGE_API_KEY=<your-lineage-api-key>
OPENLINEAGE_NAMESPACE=<NAMESPACE_NAME> # Replace with the name of your dbt project.
# Astronomer recommends using a meaningful namespace such as `dbt-dev` or `dbt-prod`.Run the following command to generate the
catalog.jsonfile for your dbt project:$ dbt docs generateIn your dbt project, run the OpenLineage wrapper script using the
dbt runcommand:$ dbt-ol run
Verify Setup
To confirm that your setup is successful, run a dbt model in your project. After you run this model, open the Lineage tab in the Cloud UI and go to the Explore page. If the setup is successful, the run that you triggered appears in the Most Recent Runs table.
This guide outlines how to set up lineage collection for a running Great Expectations suite.
Prerequisites
- A Great Expectations suite.
- Your Astro base domain.
- Your Organization's OpenLineage API key.
Setup
Update your
great_expectations.ymlfile to addOpenLineageValidationActionto youraction_list_operatorconfiguration:validation_operators:
action_list_operator:
class_name: ActionListValidationOperator
action_list:
- name: openlineage
action:
class_name: OpenLineageValidationAction
module_name: openlineage.common.provider.great_expectations
openlineage_host: https://<your-astro-base-domain>
openlineage_apiKey: <your-lineage-api-key>
openlineage_namespace: <NAMESPACE_NAME> # Replace with your job namespace; Astronomer recommends using a meaningful namespace such as `dev` or `prod`.
job_name: validate_my_datasetLineage support for GreatExpectations requires the use of the
ActionListValidationOperator. In each of your checkpoint's xml files incheckpoints/, set thevalidation_operator_nameconfiguration toaction_list_operator:name: check_users
config_version:
module_name: great_expectations.checkpoint
class_name: LegacyCheckpoint
validation_operator_name: action_list_operator
batches:
- batch_kwargs:
Verify
To confirm that your setup is successful, open the Lineage tab in the Cloud UI and go to the Issues page. Recent data quality assertion issues appear in the All Issues table.
If your code hasn't produced any data quality assertion issues, use the search bar to search for a dataset and view its node on the lineage graph for a recent job run. Click the Quality tab to view metrics and assertion pass or fail counts.
This guide outlines how to set up lineage collection for Spark.
Prerequisites
- A Spark application.
- A Spark job.
- Your Astro base domain.
- Your Organization's OpenLineage API key.
Setup
In your Spark application, set the following properties to configure your lineage endpoint, install the openlineage-spark library, and configure an OpenLineageSparkListener:
SparkSession.builder \
.config('spark.jars.packages', 'io.openlineage:openlineage-spark:0.2.+')
.config('spark.extraListeners', 'io.openlineage.spark.agent.OpenLineageSparkListener')
.config('spark.openlineage.host', 'https://<your-astro-base-domain>')
.config('spark.openlineage.apiKey', '<your-lineage-api-key>')
.config('spark.openlineage.namespace', '<NAMESPACE_NAME>') # Replace with the name of your Spark cluster.
.getOrCreate() # Astronomer recommends using a meaningful namespace such as `spark-dev` or `spark-prod`.
Verify
To confirm that your setup is successful, run a Spark job after you save your configuration. After you run this model, open the Lineage tab in the Cloud UI and go to the Explore page. Your recent Spark job run appears in the Most Recent Runs table.
Make source code visible for Airflow operators
Because Workspace permissions are not yet applied to the Lineage tab, viewing source code for supported Airflow operators is off by default. If you want users across Workspaces to be able to view source code for Airflow tasks in a given Deployment, create an environment variable in the Deployment with a key of OPENLINEAGE_AIRFLOW_DISABLE_SOURCE_CODE and a value of False. Astronomer recommends enabling this feature only for Deployments with non-sensitive code and workflows.