Orchestrate Snowflake Queries with Airflow
Snowflake is one of the most commonly used data warehouses. Orchestrating Snowflake queries as part of a data pipeline is one of the most common Airflow use cases. Using Airflow with Snowflake is straightforward, and there are multiple open source packages, tools, and integrations that can help you realize the full potential of your existing Snowflake instance.
This guide covers the following topics:
- Using Snowflake providers and the available modules, and how to implement deferrable versions of common operators.
- Leveraging the OpenLineage Airflow integration to get data lineage and enhanced observability from your Snowflake jobs.
- Using the Astro SDK for the next generation of DAG authoring for Snowflake query tasks.
- General best practices and considerations when interacting with Snowflake from Airflow.
Using Snowflake providers
The following are some of the open source packages that you can use to orchestrate Snowflake in Airflow:
- The Snowflake provider package is maintained by the Airflow community and contains hooks, operators, and transfer operators for Snowflake.
- The Astronomer Providers package contains deferrable operators built and maintained by Astronomer, including a deferrable version of the
SnowflakeOperator. - The Common SQL provider package contains SQL check operators that you can use to perform data quality checks against Snowflake data.
To leverage all of the available Snowflake modules, install all three packages in your Airflow environment. If you use the Astro CLI, add the following three lines to your Astro project requirements.txt file:
apache-airflow-providers-snowflake
apache-airflow-providers-common-sql
astronomer-providers[snowflake]
The following are the available modules for orchestrating basic queries and functions in Snowflake:
SnowflakeOperator: Executes a SQL query in Snowflake. This operator is part ofapache-airflow-providers-snowflake.S3ToSnowflakeOperator: Executes a COPY command to transfer data from S3 into Snowflake.SnowflakeToSlackOperator: Executes a SQL query in Snowflake and sends the results to Slack.SnowflakeOperatorAsync: The deferrable version of theSnowflakeOperator, executes a SQL query in Snowflake.SnowflakeHook: A hook abstracting the Snowflake API. Generally, you only need to use this hook when creating a custom operator or function. This hook is part ofapache-airflow-providers-snowflake.SnowflakeHookAsync: The deferrable version of theSnowflakeHook, abstracts the Snowflake API.
The following are the available modules for orchestrating data quality checks in Snowflake:
SQLColumnCheckOperator: Performs a data quality check against columns of a given table. Using this operator with Snowflake requires a Snowflake connection ID, the name of the table to run checks on, and acolumn_mappingdescribing the relationship between columns and tests to run.SQLTableCheckOperator: Performs a data quality check against a given table. Using this operator with Snowflake requires a Snowflake connection ID, the name of the table to run checks on, and a checks dictionary describing the relationship between the table and the tests to run.
Although the apache-airflow-providers-snowflake package contains operators that you can use to run data quality checks in Snowflake, Astronomer recommends that you use apache-airflow-providers-common-sql instead for its additional flexibility and community support. For more information about using the SQL check operators, see Airflow Data Quality Checks with SQL Operators.
Example Implementation
Example code using various Snowflake operators can be found on the Astronomer Registry.
The following example DAG runs a write, audit, and publish pattern to showcase loading and quality checking Snowflake data. The DAG completes the following steps:
- Simultaneously create tables in Snowflake for the production data and the raw data that needs to be audited using the
SnowflakeOperator. These tasks are not implemented with the deferrable version of theSnowflakeOperatorbecauseCREATE TABLEstatements typically run very quickly. - Load data into the audit table using the
SnowflakeOperatorAsync. This task is deferred to save on computational resources, because loading data can take some time if the dataset is large. To use the deferrable operator, you must have a triggerer running in your Airflow environment. - Run data quality checks on the audit table to ensure that no erroneous data is moved to production. This task group includes column checks using the
SQLColumnCheckOperatorand table checks using theSQLTableCheckOperator. - If the data quality checks are passed, copy data from the audit table into the production table using the
SnowflakeOperatorAsync. - Delete the audit table because it only contains temporary data.
All of these tasks rely on parameterized SQL scripts that are stored in the include/sql/ directory and can be found on the Astronomer Registry.
import json
from pendulum import datetime
from pathlib import Path
from airflow import DAG
from airflow.models.baseoperator import chain
from airflow.operators.empty import EmptyOperator
from airflow.providers.snowflake.operators.snowflake import SnowflakeOperator
from astronomer.providers.snowflake.operators.sensors.snowflake import SnowflakeOperatorAsync
from airflow.providers.common.sql.operators import SQLColumnCheckOperator, SQLTableCheckOperator
from airflow.utils.task_group import TaskGroup
from include.libs.schema_reg.base_schema_transforms import snowflake_load_column_string
SNOWFLAKE_FORESTFIRE_TABLE = "forestfires"
SNOWFLAKE_AUDIT_TABLE = f"{SNOWFLAKE_FORESTFIRE_TABLE}_AUDIT"
SNOWFLAKE_CONN_ID = "snowflake_default"
base_path = Path(__file__).parents[2]
table_schema_path = (
f"{base_path}/include/sql/snowflake_examples/table_schemas/"
)
with DAG(
"snowflake_write_audit_publish",
description="Example DAG showcasing loading and data quality checking with Snowflake.",
start_date=datetime(2021, 1, 1),
schedule_interval=None,
template_searchpath="/usr/local/airflow/include/sql/snowflake_examples/",
catchup=False,
default_args={"conn_id": SNOWFLAKE_CONN_ID, "snowflake_conn_id": SNOWFLAKE_CONN_ID}
) as dag:
create_forestfire_audit_table = SnowflakeOperator(
task_id="create_forestfire_audit_table",
sql="create_forestfire_table.sql",
params={"table_name": SNOWFLAKE_AUDIT_TABLE},
)
create_forestfire_production_table = SnowflakeOperator(
task_id="create_forestfire_production_table",
sql="create_forestfire_table.sql",
params={"table_name": SNOWFLAKE_FORESTFIRE_TABLE}
)
load_data = SnowflakeOperatorAsync(
task_id="insert_query",
sql="load_snowflake_forestfire_data.sql",
params={"table_name": SNOWFLAKE_AUDIT_TABLE}
)
with TaskGroup(group_id="quality_checks") as quality_check_group:
column_checks = SQLColumnCheckOperator(
task_id="column_checks",
table=SNOWFLAKE_AUDIT_TABLE,
column_mapping={"id": {"null_check": {"equal_to": 0}}}
)
table_checks = SQLTableCheckOperator(
task_id="table_checks",
table=SNOWFLAKE_AUDIT_TABLE,
checks={"row_count_check": {"check_statement": "COUNT(*) = 9"}}
)
with open(
f"{table_schema_path}/forestfire_schema.json",
"r",
) as f:
table_schema = json.load(f).get("forestfire")
table_props = table_schema.get("properties")
table_dimensions = table_schema.get("dimensions")
table_metrics = table_schema.get("metrics")
col_string = snowflake_load_column_string(table_props)
copy_snowflake_audit_to_production_table = SnowflakeOperator(
task_id="copy_snowflake_audit_to_production_table",
sql="copy_forestfire_snowflake_audit.sql",
params={
"table_name": SNOWFLAKE_FORESTFIRE_TABLE,
"audit_table_name": f"{SNOWFLAKE_FORESTFIRE_TABLE}_AUDIT",
"table_schema": table_props,
"col_string": col_string,
},
trigger_rule="all_success"
)
delete_audit_table = SnowflakeOperator(
task_id="delete_audit_table",
sql="delete_forestfire_table.sql",
params={"table_name": f"{SNOWFLAKE_FORESTFIRE_TABLE}_AUDIT"},
trigger_rule="all_success"
)
begin = EmptyOperator(task_id="begin")
end = EmptyOperator(task_id="end")
chain(
begin,
[create_forestfire_production_table, create_forestfire_audit_table],
load_data,
quality_check_group,
copy_snowflake_audit_to_production_table,
delete_audit_table,
end
)

To run this DAG, you need an Airflow connection to your Snowflake instance. This DAG uses a connection named snowflake_default. Your connection should have a type of Snowflake include the following information:
Host: <your-snowflake-host> # For example, `account.region.snowflakecomputing.com`
Schema: <your-schema>
Login: <your-login>
Password: <your-password>
Account: <your-snowflake-account>
Database: <your-database>
Region: <your-account-region>
Role: <your-role>
Warehouse: <your-warehouse>
Enhanced Observability with OpenLineage
The OpenLineage project integration with Airflow lets you obtain and view lineage data from your Airflow tasks. As long as an extractor exists for the operator being used, lineage data is generated automatically from each task instance. For an overview of how OpenLineage works with Airflow, see OpenLineage and Airflow.
Because SnowflakeOperator and SnowflakeOperatorAsync have an extractor, you can use lineage metadata to answer the following questions across DAGs:
- How does data stored in Snowflake flow through my DAGs? Are there any upstream dependencies?
- What downstream data does a task failure impact?
- Where did a change in data format originate?
This image shows an overview of the interaction between OpenLineage,Airflow and Snowflake:
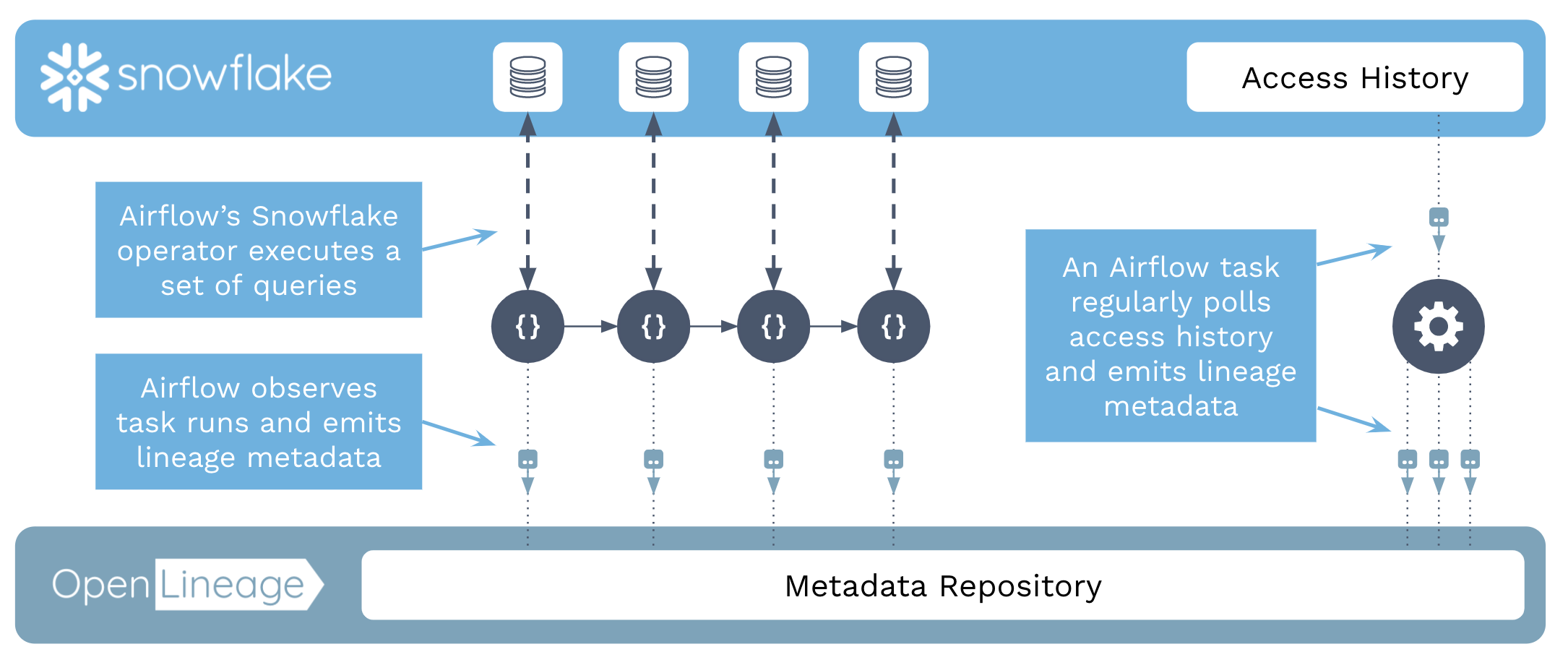
To view lineage data from your DAGs, you need to have OpenLineage installed in your Airflow environment and a lineage front end running. If you're using Astro users, lineage is enabled automatically. If you're using open source tools, you can run Marquez locally and connect it to your Airflow environment. See OpenLineage and Airflow.
To show an example of lineage resulting from Snowflake orchestration, you'll look at the write, audit, publish DAG from the previous example. The following image shows the Datakin UI integrated with Astro, but Marquez will show similar information.
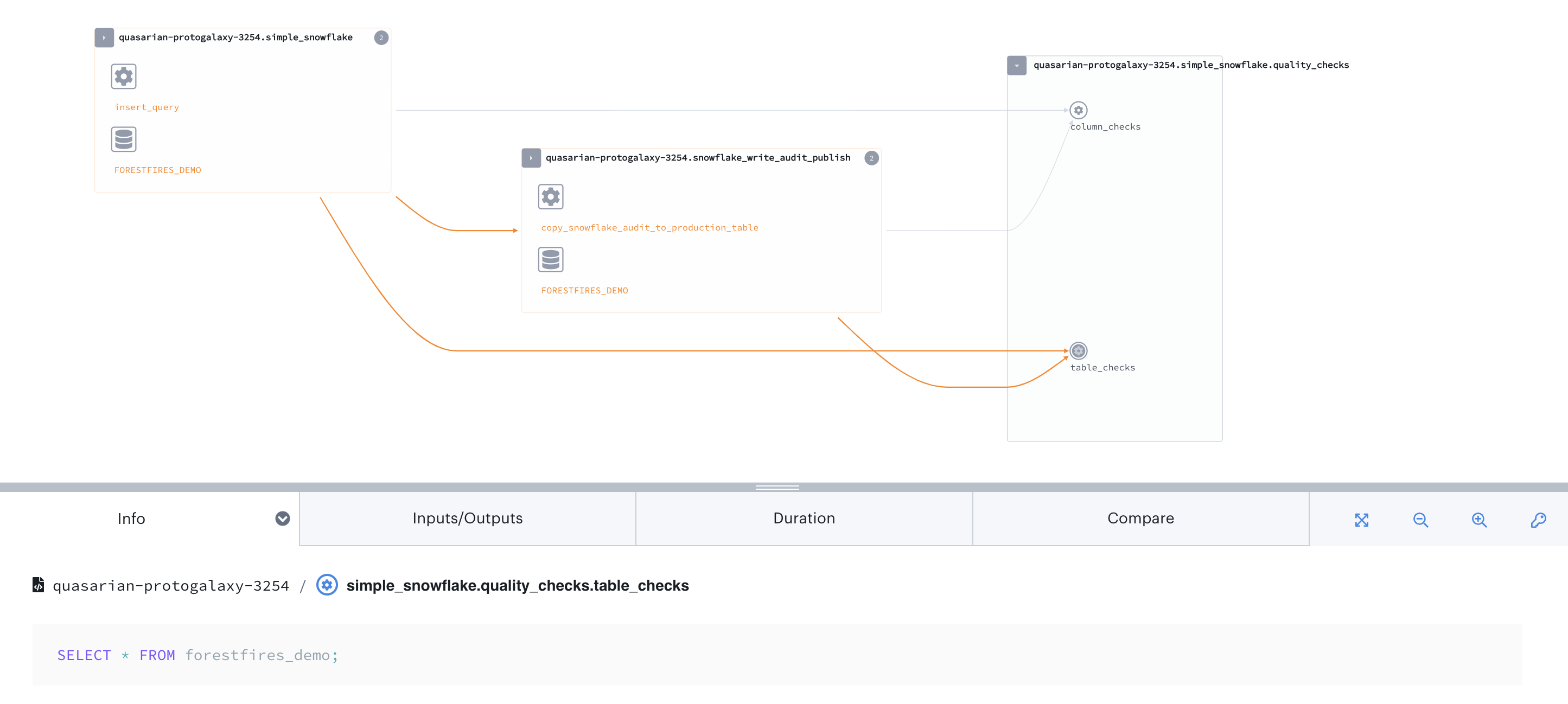
Looking at the lineage graph, you can see the flow of data from the creation of the table, to the insertion of data, to the data quality checks. If a failure occurs during the data quality checks or elsewhere, the lineage graph identifies the affected datasets. If your work on this dataset expanded into other DAGs in Airflow, you would see those connections here as well.
DAG Authoring with the Astro Python SDK
The Astro Python SDK is an open source DAG authoring tool maintained by Astronomer that simplifies the data transformation process between different environments, so you can focus solely on writing execution logic without worrying about Airflow orchestration logic. Details such as creating dataframes, storing intermediate results, passing context and data between tasks, and creating Airflow task dependencies are all managed automatically.
The Astro Python SDK supports Snowflake as a data warehouse and can be used to simplify ETL workflows with Snowflake. For example, the following DAG moves data from Amazon S3 into Snowflake, performs some data transformations, and loads the resulting data into a reporting table.
from pendulum import datetime
from airflow.models import DAG
from pandas import DataFrame
from astro import sql as aql
from astro.files import File
from astro.sql.table import Table
S3_FILE_PATH = "s3://<aws-bucket-name>"
S3_CONN_ID = "aws_default"
SNOWFLAKE_CONN_ID = "snowflake_default"
SNOWFLAKE_ORDERS = "orders_table"
SNOWFLAKE_FILTERED_ORDERS = "filtered_table"
SNOWFLAKE_JOINED = "joined_table"
SNOWFLAKE_CUSTOMERS = "customers_table"
SNOWFLAKE_REPORTING = "reporting_table"
@aql.transform
def filter_orders(input_table: Table):
return "SELECT * FROM {{input_table}} WHERE amount > 150"
@aql.transform
def join_orders_customers(filtered_orders_table: Table, customers_table: Table):
return """SELECT c.customer_id, customer_name, order_id, purchase_date, amount, type
FROM {{filtered_orders_table}} f JOIN {{customers_table}} c
ON f.customer_id = c.customer_id"""
@aql.dataframe
def transform_dataframe(df: DataFrame):
purchase_dates = df.loc[:, "purchase_date"]
print("purchase dates:", purchase_dates)
return purchase_dates
with DAG(
dag_id="astro_orders",
start_date=datetime(2019, 1, 1),
schedule_interval="@daily",
catchup=False,
) as dag:
# Extract a file with a header from S3 into a Table object
orders_data = aql.load_file(
# data file needs to have a header row
input_file=File(
path=S3_FILE_PATH + "/orders_data_header.csv", conn_id=S3_CONN_ID
),
output_table=Table(conn_id=SNOWFLAKE_CONN_ID),
)
# create a Table object for customer data in our Snowflake database
customers_table = Table(
name=SNOWFLAKE_CUSTOMERS,
conn_id=SNOWFLAKE_CONN_ID,
)
# filter the orders data and then join with the customer table
joined_data = join_orders_customers(filter_orders(orders_data), customers_table)
# merge the joined data into our reporting table, based on the order_id .
# If there's a conflict in the customer_id or customer_name then use the ones from
# the joined data
reporting_table = aql.merge(
target_table=Table(
name=SNOWFLAKE_REPORTING,
conn_id=SNOWFLAKE_CONN_ID,
),
source_table=joined_data,
target_conflict_columns=["order_id"],
columns=["customer_id", "customer_name"],
if_conflicts="update",
)
purchase_dates = transform_dataframe(reporting_table)
Using Astro SDK aql functions, you are able to seamlessly transition between SQL transformations (filter_orders and join_orders_customers) to Python dataframe transformations (transform_dataframe). All intermediary data created by each task is automatically stored in Snowflake and made available to downstream tasks.
For more detailed instructions on running this example DAG, see Astro SDK Getting Started.
Best practices and considerations
The following are some best practices and considerations to keep in mind when orchestrating Snowflake queries from Airflow:
- To reduce costs and improve the scalability of your Airflow environment, use the deferrable version of operators.
- Set your default Snowflake query specifications such as Warehouse, Role, Schema, and so on in the Airflow connection. Then overwrite those parameters for specific tasks as necessary in your operator definitions. This is cleaner and easier to read than adding
USE Warehouse XYZ;statements within your queries. - Pay attention to which Snowflake compute resources your tasks are using, as overtaxing your assigned resources can cause slowdowns in your Airflow tasks. It is generally recommended to have different warehouses devoted to your different Airflow environments to ensure DAG development and testing does not interfere with DAGs running in production.
- Make use of Snowflake stages when loading data from an external system using Airflow. Transfer operators such as the
S3ToSnowflakeoperator require a Snowflake stage be set up. Stages generally make it much easier to repeatedly load data in a specific format.