Airflow components
When working with Airflow, understanding the underlying infrastructure components and how they function can help you develop and run your DAGs, troubleshoot issues, and successfully run Airflow.
In this guide, you'll learn about the core components of Airflow and how to manage Airflow infrastructure for high availability. Some of the components and features described in this topic are unavailable in earlier Airflow versions.
Assumed knowledge
To get the most out of this guide, you should have an understanding of:
- Basic Airflow concepts. See Introduction to Apache Airflow.
Core components
The following Apache Airflow core components are running at all times:
- Webserver: A Flask server running with Gunicorn that serves the Airflow UI.
- Scheduler: A Daemon responsible for scheduling jobs. This is a multi-threaded Python process that determines what tasks need to be run, when they need to be run, and where they are run.
- Database: A database where all DAG and task metadata are stored. This is typically a Postgres database, but MySQL, MsSQL, and SQLite are also supported.
- Executor: The mechanism for running tasks. An executor is running within the scheduler whenever Airflow is operational.
If you run Airflow locally using the Astro CLI, you'll notice that when you start Airflow using astrocloud dev start, it will spin up three containers, one for each of the core components.
In addition to these core components, there are a few situational components that are used only to run tasks or make use of certain features:
- Worker: The process that executes tasks, as defined by the executor. Depending on which executor you choose, you may or may not have workers as part of your Airflow infrastructure.
- Triggerer: A separate process which supports deferrable operators. This component is optional and must be run separately. It is needed only if you plan to use deferrable (or "asynchronous") operators.
The following diagram illustrates component interaction:
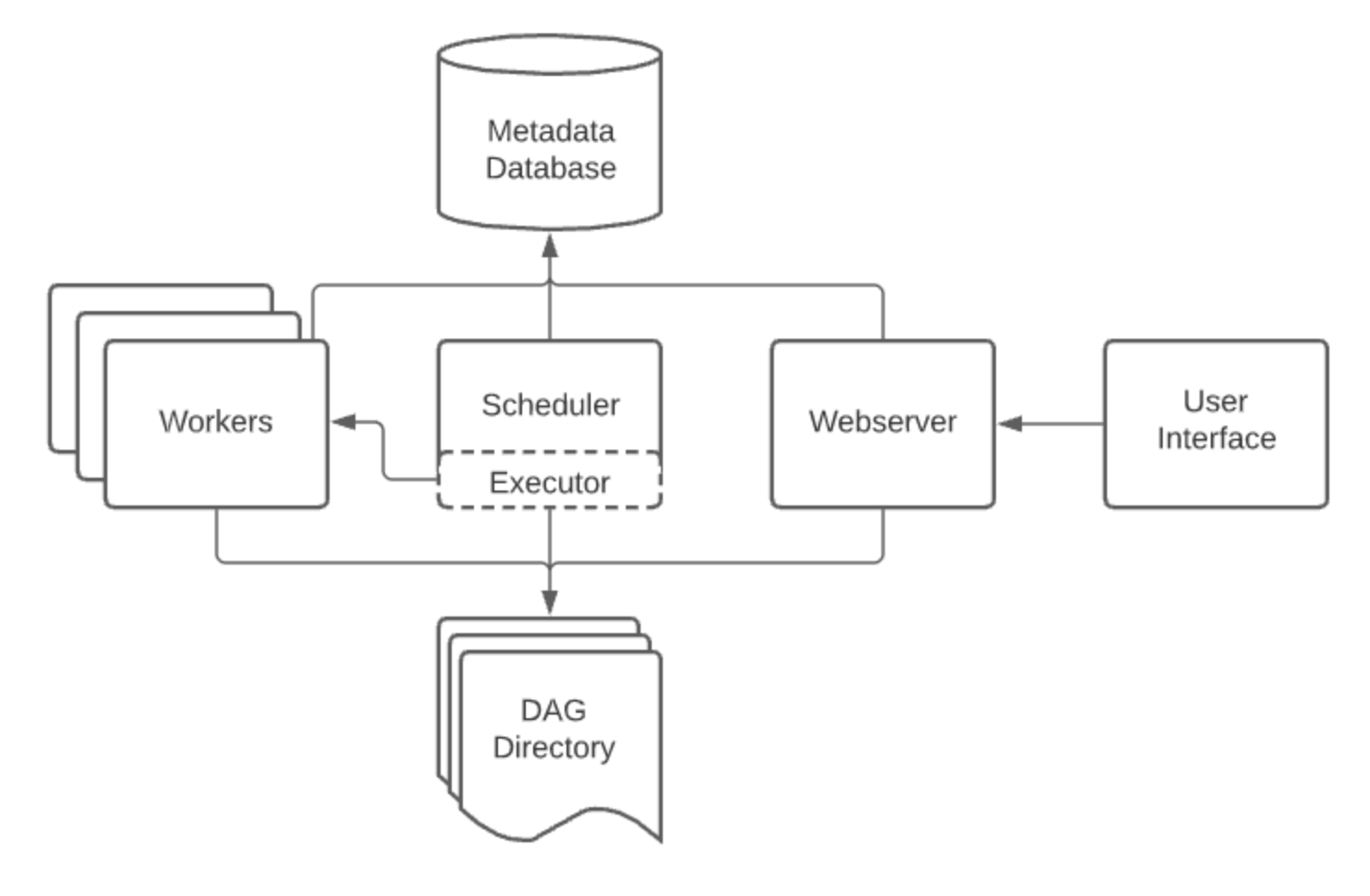
Executors
You can use preconfigured Airflow executors, or you can create a custom executor. Each executor has a specific purpose:
SequentialExecutor: Executes tasks sequentially inside the scheduler process, with no parallelism or concurrency. This is the default in Airflow executor.
LocalExecutor: Executes tasks locally inside the scheduler process, but supports parallelism and hyperthreading. This executor is recommended for testing Airflow on a local computer or on a single node.
CeleryExecutor: Uses a Celery backend (such as Redis, RabbitMq, or another message queue system) to coordinate tasks between preconfigured workers. This executor is ideal for high volumes of shorter running tasks or in environments with consistent task loads.
KubernetesExecutor: Calls the Kubernetes API to create a separate pod for each task to run, enabling users to pass in custom configurations for each of their tasks and use resources efficiently. This executor is ideal in the following scenarios:
- You have long running tasks that you don't want to be interrupted by code deploys or Airflow updates.
- Your tasks require very specific resource configurations.
- Your tasks run infrequently, and you don't want to incur worker resource costs when they aren't running.
The CeleryKubernetes Executor and the Dask Executor are considered more experimental and are not as widely adopted as the other executors.
Managing Airflow infrastructure
All Airflow components should be run on an infrastructure that is appropriate for the requirements of your organization. For example, using the Astro CLI to run Airflow on a local computer can be helpful when testing and for DAG development, but it is insufficient to support running DAGs in production.
The following resources can help you manage Airflow components:
- OSS Production Docker Images
- OSS Official Helm Chart
- Managed Airflow on Astro
Scalability is also an important consideration when setting up your production Airflow environment. See Scaling out Airflow.
High availability
Airflow can be made highly available, which makes it suitable for large organizations with critical production workloads. Airflow 2 introduced a highly available scheduler, meaning that you can run multiple Scheduler replicas in an active-active model. This makes the scheduler more performant and resilient, eliminating a single point of failure within your Airflow environment.
Running multiple schedulers requires additional database configuration. See Running More Than One Scheduler.