Introduction to Airflow decorators
Since Airflow 2.0, decorators have been available for some functions as an alternative DAG authoring experience to traditional operators. In Python, decorators are functions that take another function as an argument and extend the behavior of that function. In the context of Airflow, decorators provide a simpler, cleaner way to define your tasks and DAG.
In this guide, you'll learn about the benefits of decorators, the decorators available in Airflow, and decorators provided in the Astronomer open source astro library. You'll also review examples and learn when you should use decorators and how you can combine them with traditional operators in a DAG.
Assumed knowledge
To get the most out of this guide, you should have an understanding of:
- Airflow operators. See Operators 101.
- Basic Python. See the Python Documentation.
When to use decorators
The purpose of decorators in Airflow is to simplify the DAG authoring experience by eliminating the boilerplate code required by traditional operators. The result can be cleaner DAG files that are more concise and easier to read. Currently, decorators can be used for Python and SQL functions.
In general, whether to use decorators is a matter of developer preference and style. Generally, a decorator and the corresponding traditional operator will have the same functionality. One exception to this is the astro library of decorators (more on these below), which do not have equivalent traditional operators. You can also easily mix decorators and traditional operators within your DAG if your use case requires that.
How to use Airflow decorators
Airflow decorators were introduced as part of the TaskFlow API, which also handles passing data between tasks using XCom and inferring task dependencies automatically. To learn more about the TaskFlow API, check out this Astronomer webinar or this Apache Airflow TaskFlow API tutorial.
Using decorators to define your Python functions as tasks is easy. Let's take a before and after example. In the "traditional" DAG below, there is a basic ETL flow with tasks to get data from an API, process the data, and store it.
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
import json
from typing import Dict
import requests
import logging
API = "https://api.coingecko.com/api/v3/simple/price?ids=bitcoin&vs_currencies=usd&include_market_cap=true&include_24hr_vol=true&include_24hr_change=true&include_last_updated_at=true"
def _extract_bitcoin_price():
return requests.get(API).json()['bitcoin']
def _process_data(ti):
response = ti.xcom_pull(task_ids='extract_bitcoin_price')
logging.info(response)
processed_data = {'usd': response['usd'], 'change': response['usd_24h_change']}
ti.xcom_push(key='processed_data', value=processed_data)
def _store_data(ti):
data = ti.xcom_pull(task_ids='process_data', key='processed_data')
logging.info(f"Store: {data['usd']} with change {data['change']}")
with DAG('classic_dag', schedule_interval='@daily', start_date=datetime(2021, 12, 1), catchup=False) as dag:
extract_bitcoin_price = PythonOperator(
task_id='extract_bitcoin_price',
python_callable=_extract_bitcoin_price
)
process_data = PythonOperator(
task_id='process_data',
python_callable=_process_data
)
store_data = PythonOperator(
task_id='store_data',
python_callable=_store_data
)
extract_bitcoin_price >> process_data >> store_data
You can now rewrite this DAG using decorators, which will eliminate the need to explicitly instantiate PythonOperators.
from airflow.decorators import dag, task
from datetime import datetime
from typing import Dict
import requests
import logging
API = "https://api.coingecko.com/api/v3/simple/price?ids=bitcoin&vs_currencies=usd&include_market_cap=true&include_24hr_vol=true&include_24hr_change=true&include_last_updated_at=true"
@dag(schedule_interval='@daily', start_date=datetime(2021, 12, 1), catchup=False)
def taskflow():
@task(task_id='extract', retries=2)
def extract_bitcoin_price() -> Dict[str, float]:
return requests.get(API).json()['bitcoin']
@task(multiple_outputs=True)
def process_data(response: Dict[str, float]) -> Dict[str, float]:
logging.info(response)
return {'usd': response['usd'], 'change': response['usd_24h_change']}
@task
def store_data(data: Dict[str, float]):
logging.info(f"Store: {data['usd']} with change {data['change']}")
store_data(process_data(extract_bitcoin_price()))
dag = taskflow()
The resulting DAG has much less code and is easier to read. Notice that it also doesn't require using ti.xcom_pull and ti.xcom_push to pass data between tasks. This is all handled by the TaskFlow API when you define your task dependencies with store_data(process_data(extract_bitcoin_price())).
Here are some other things to keep in mind when using decorators:
For any decorated object in your DAG file, you must call them so that Airflow can register the task or DAG (e.g.
dag = taskflow()).When you define a task, the
task_idwill default to the name of the function you decorated. If you want to change that, you can simply pass atask_idto the decorator as you did in theextracttask above. Similarly, other task level parameters such as retries or pools can be defined within the decorator (see the example withretriesabove).You can decorate a function that is imported from another file with something like the following:
from include.my_file import my_function
@task
def taskflow_func():
my_function()This is recommended in cases where you have lengthy Python functions since it will make your DAG file easier to read.
Mixing decorators with traditional operators
If you have a DAG that uses PythonOperator and other operators that don't have decorators, you can easily combine decorated functions and traditional operators in the same DAG. For example, you can add an EmailOperator to the previous example by updating your code to the following:
from airflow.decorators import dag, task
from airflow.operators.email_operator import EmailOperator
from datetime import datetime
from typing import Dict
import requests
import logging
API = "https://api.coingecko.com/api/v3/simple/price?ids=bitcoin&vs_currencies=usd&include_market_cap=true&include_24hr_vol=true&include_24hr_change=true&include_last_updated_at=true"
@dag(schedule_interval='@daily', start_date=datetime(2021, 12, 1), catchup=False)
def taskflow():
@task(task_id='extract', retries=2)
def extract_bitcoin_price() -> Dict[str, float]:
return requests.get(API).json()['bitcoin']
@task(multiple_outputs=True)
def process_data(response: Dict[str, float]) -> Dict[str, float]:
logging.info(response)
return {'usd': response['usd'], 'change': response['usd_24h_change']}
@task
def store_data(data: Dict[str, float]):
logging.info(f"Store: {data['usd']} with change {data['change']}")
email_notification = EmailOperator(
task_id='email_notification',
to='noreply@astronomer.io',
subject='dag completed',
html_content='the dag has finished'
)
store_data(process_data(extract_bitcoin_price())) >> email_notification
dag = taskflow()
Note that when adding traditional operators, dependencies are still defined using bitshift operators.
Astro Python SDK decorators
The Astro Python SDK provides decorators and modules that allow data engineers to think in terms of data transformations rather than Airflow concepts when writing DAGs. The goal is to allow DAG writers to focus on defining execution logic without having to worry about orchestration logic.
The library contains SQL and dataframe decorators that greatly simplify your DAG code and allow you to directly define tasks without boilerplate operator code. It also allows you to transition seamlessly between SQL and Python for transformations without having to explicitly pass data between tasks or convert the results of queries to dataframes and vice versa. For a full description of functionality, check out the repo Readme.
To use the Astro Python SDK, you need to install the astro-sdk-python package in your Airflow environment and enable pickling (AIRFLOW__CORE__ENABLE_XCOM_PICKLING=True).
To show the Astro Python SDK in action, we'll use a simple ETL example. We have homes data in two different CSVs that we need to aggregate, clean, transform, and append to a reporting table. Some of these tasks are better suited to SQL, and some to Python, but we can easily combine both using astro-sdk-python functions. The DAG looks like this:
import os
from datetime import datetime
import pandas as pd
from airflow.decorators import dag
from astro.files import File
from astro.sql import (
append,
cleanup,
dataframe,
drop_table,
load_file,
run_raw_sql,
transform,
)
from astro.sql.table import Metadata, Table
SNOWFLAKE_CONN_ID = "snowflake_conn"
FILE_PATH = "/usr/local/airflow/include/"
# The first transformation combines data from the two source csv's
@transform
def extract_data(homes1: Table, homes2: Table):
return """
SELECT *
FROM {{homes1}}
UNION
SELECT *
FROM {{homes2}}
"""
# Switch to Python (Pandas) for melting transformation to get data into long format
@dataframe
def transform_data(df: pd.DataFrame):
df.columns = df.columns.str.lower()
melted_df = df.melt(
id_vars=["sell", "list"], value_vars=["living", "rooms", "beds", "baths", "age"]
)
return melted_df
# Back to SQL to filter data
@transform
def filter_data(homes_long: Table):
return """
SELECT *
FROM {{homes_long}}
WHERE SELL > 200
"""
@run_raw_sql
def create_table():
"""Create the reporting data which will be the target of the append method"""
return """
CREATE TABLE IF NOT EXISTS homes_reporting (
sell number,
list number,
variable varchar,
value number
);
"""
@dag(start_date=datetime(2021, 12, 1), schedule_interval="@daily", catchup=False)
def example_snowflake_partial_table_with_append():
# Initial load of homes data csv's into Snowflake
homes_data1 = load_file(
input_file=File(path=FILE_PATH + "homes.csv"),
output_table=Table(
name="HOMES",
conn_id=SNOWFLAKE_CONN_ID
),
)
homes_data2 = load_file(
task_id="load_homes2",
input_file=File(path=FILE_PATH + "homes2.csv"),
output_table=Table(
name="HOMES2",
conn_id=SNOWFLAKE_CONN_ID
),
)
# Define task dependencies
extracted_data = extract_data(
homes1=homes_data1,
homes2=homes_data2,
output_table=Table(name="combined_homes_data"),
)
transformed_data = transform_data(
df=extracted_data, output_table=Table(name="homes_data_long")
)
filtered_data = filter_data(
homes_long=transformed_data,
output_table=Table(name="expensive_homes_long"),
)
create_results_table = create_table(conn_id=SNOWFLAKE_CONN_ID)
# Append transformed & filtered data to reporting table
# Dependency is inferred by passing the previous `filtered_data` task to `append_table` param
record_results = append(
source_table=filtered_data,
target_table=Table(name="homes_reporting", conn_id=SNOWFLAKE_CONN_ID),
columns=["sell", "list", "variable", "value"],
)
record_results.set_upstream(create_results_table)
example_snowflake_partial_table_dag = example_snowflake_partial_table_with_append()
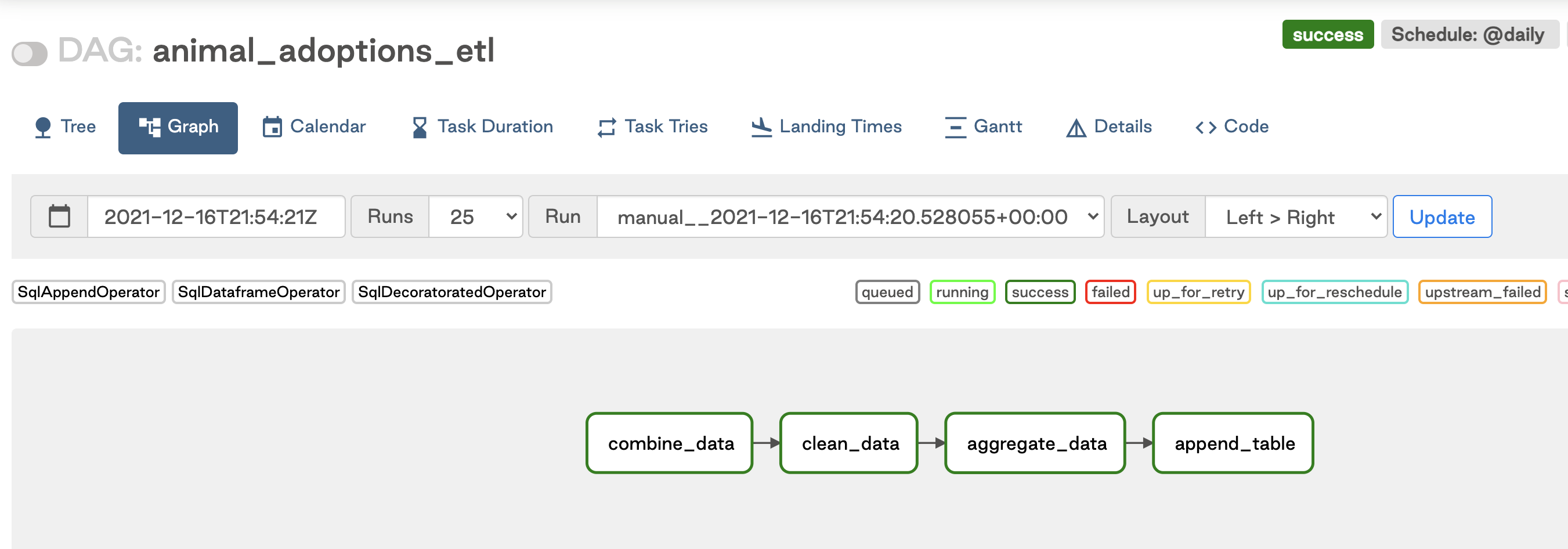
The general steps in the DAG are:
- Combine data from your two source tables. You use a
transform()function since you are running a SQL statement on tables that already exist in our database. You define the source tables with theTable()parameter when you call the function (center_1=Table('ADOPTION_CENTER_1', conn_id="snowflake", schema='SANDBOX_KENTEND')). - Run another
transform()function to clean the data; you don't report on guinea pig adoptions in this example, so you'll remove them from the dataset. Eachtransformfunction will store results in a table in your database. You can specify anoutput_tableto store the results in a specific table, or you can letastrocreate a table in a default temporary schema for you by not defining any output. - Transform the data by pivoting using Python. Pivoting is notoriously difficult in Snowflake, so you seamlessly switch to Pandas. In this task you specify an
output_tablethat you want the results stored in. - Append the results to an existing reporting table using the
appendfunction. Because you pass the results of the previous function (aggregated_data) to theappend_dataparameter,astroinfers a dependency between the tasks. You don't need to explicitly define the dependency yourself.
By defining your task dependencies when calling the functions (for example, cleaned_data = clean_data(combined_data)), astro takes care of passing all context and metadata between the tasks. The result is a DAG where you accomplished some tricky transformations without having to write a lot of Airflow code or transition between SQL and Python.
List of available Airflow decorators
There are a limited number of decorators available to use with Airflow, although more will be added in the future. This list provides a reference of what is currently available so you don't have to dig through source code:
- Astro Python SDK SQL and dataframe decorators
- DAG decorator (
@dag()) - Task decorator (
@task()), which creates a Python task - Python Virtual Env decorator (
@task.virtualenv()), which runs your Python task in a virtual environment - Docker decorator (
@task.docker()), which creates aDockerOperatortask - TaskGroup decorator (
@task_group())
As of Airflow 2.2, you can also create your own custom task decorator.